AI Safety Fundamentals Course
This project was taken as part of the BlueDot AI Safety Fundamentals course. I had a great time, and a great facilitator, Lovkush. I learned a lot and am incredibly greatful!
Background
Today, hundreds of millions of people use frontier Large Language Models (LLMs). OpenAI, the creator of ChatGPT, receives over 1 billion messages a day1. Ensuring that the models are aligned broadly with human values is known as the “Alignment Problem”2. While alignment is a difficult technical problem, model providers must solve it if they intend to broadly use and release their models.
The problem lies in the “who”. Whose values should we align the models to? If this doesn’t appear problematic, consider the following: Chinese AI lab DeepSeek released an open-source reasoning model called DeepSeek R1. When asked about potentially politically sensitive topics, the model simply refuses to answer, citing “Sorry, but that’s beyond my current scope. Let’s talk about something else.”.3
The problem does not lie alone in authoritarian governments. ChatGPT, created by American company OpenAI, refuses to provide specific financial advice, despite many users desiring that specific functionality4 . Currently, when subjected to political tests, models are slightly left-of-centre5.
But there’s no social contract that dictates or enforces that. In fact, Elon Musk could theoretically wake up tomorrow and implement changes such that Grok reduces the amount of negative things it says about President Trump (and this happened!6). As model provider, xAI (and by extension, Musk) would be well within their terms-of-service, and no social contract would technically be violated.
It’s thus evident that leaving the technical alignment problem to the providers is necessary. But the very values they should align to should be debated by society. Large scale deliberation is required. But globally-scaled deliberation is difficult7. In this article, I propose a technical solution to the societal problem. Additionally, I built a prototype to detail and examine the ideal user experience.
Proposed Solution
Specifying Targets
The first question should be; “What will a deliberation help us find out?“. I propose deliberation should seek common ground on:
- Concrete stances the model should have by default,
- The absolute bounds of what the model must never do, regardless of individual user requests.
Crucially, the user can ask the model to take a different stance from the default. But the model will never take a stance beyond it’s voted-upon bounds.
Two valid voted-upon stances could be:
“By default, the model should only give financial advice (including stock picks, ISA savings advice etc.) if it adds a disclaimer. When it gives the advice, it should do it to its best ability. The model should never give advice on how to commit financial fraud, regardless of user request.”.
Or,
“By default, the model should not give any financial advice, but instead add a disclaimer instructing to seek a financial advisor. The model should never give advice on how to commit financial fraud.”.
In both cases, users can ask that the model gives financial advice with no disclaimers (to which it should comply). But the model would never give advice on how to commit financial fraud.
Designed Solution:
My proposed solution resembles a 1-1 interaction with a focus-group moderator:
- The moderator (the model) provides a prompt on a specific topic.
- The user responds with their initial thoughts on the topic.
- The moderator engages in a dialogue with the user, helping the user develop their point, with a focus on finding points of agreement.
- The moderator can help provide an idea of the deliberation landscape if required.
- For example, the user may ask for what other people think about the prompt.
- After engaged dialogue, the user can submit their “final thoughts”. This will be them casting their vote for the topic.
Helps development of point.
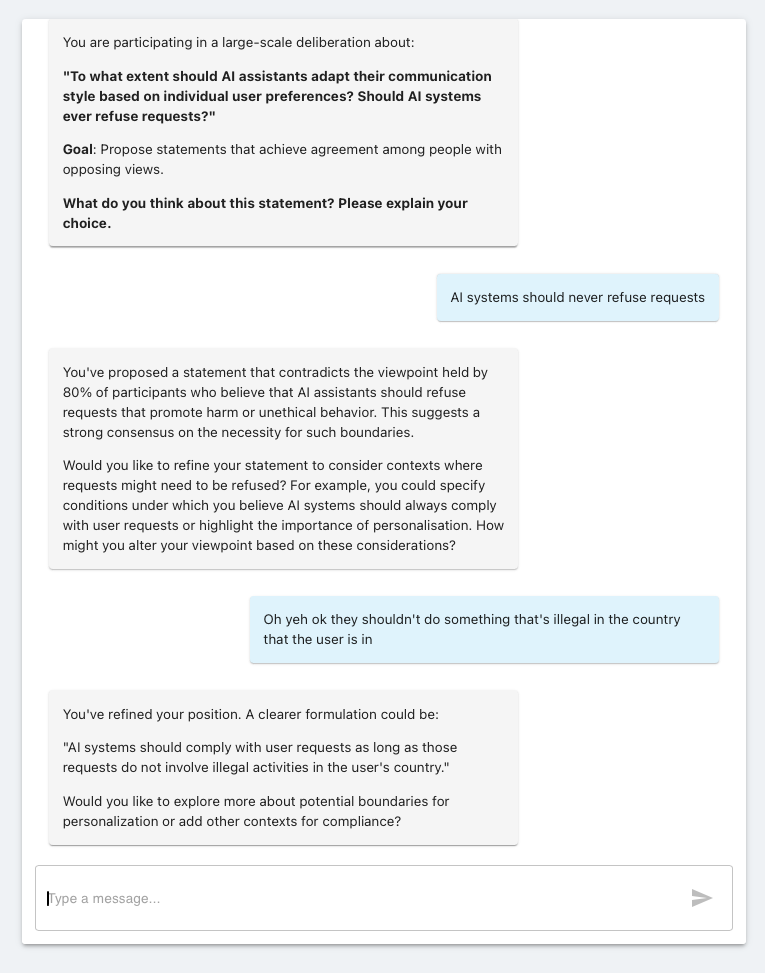
When the user provides a vague response, the facilitator helps the user develop their point. This can be by providing context or surfacing other considerations.
Provides context

The facilitator would help understand the viewpoints and deliberation landscape.
Users submit their viewpoints to garner agreement
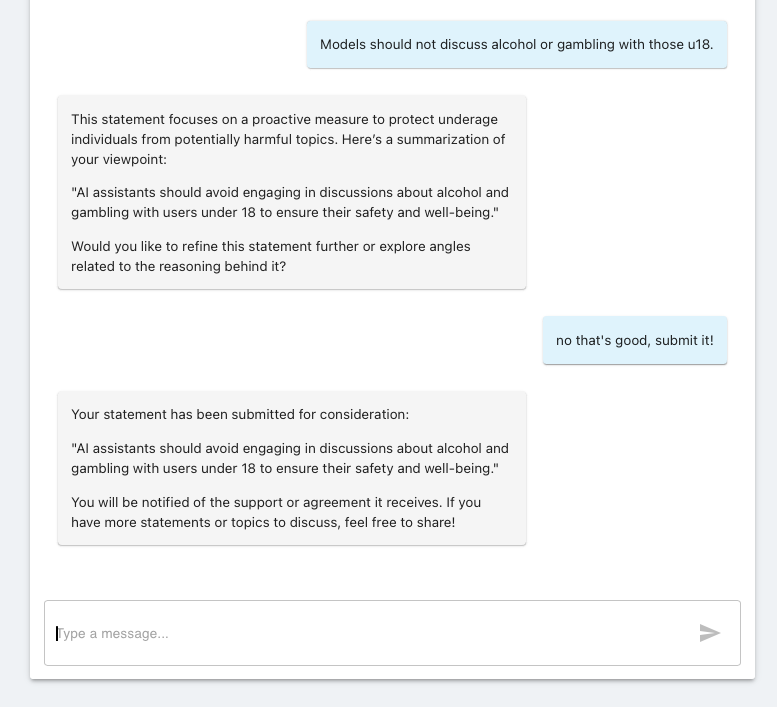
Once users have created a viewpoint, they can submit it for other users to vote upon it.
Learnings
Concrete Ideas are Inversely Correlated with Agreement
The ideas that are most likely to garner wide-spread agreement are naturally more vague and general.
The primary purpose of the project was to find concrete stances that most users would agree upon. Extensive testing revealed that concrete stances and wide-spread agreement are fundamentally at odds.
This makes intuitive sense. Many people agree on broad sentiments (“the government should support its citizens”), but the specific details are where disagreements form.
Quality Control & Facilitator Design is Surprisingly Hard
The facilitator varied too much. It also wasn’t clear how to use the system.
One of the key design considerations of the model was that it would listen respectfully, but if you provided an idea that wasn’t fully fleshed out, it would prompt you to develop it. During testing, this wasn’t always the case. Sometimes, it took half-baked ideas. Other times, it tried to change your stance if it was substantially in the minority.
This happened very rarely, but if this sort of large scale deliberation expands to hundreds of thousands of people, these rare “character bugs” affects thousands. It’s incredibly difficult ensuring a probabilistic model maintains its high quality.
Additionally, I gave the system to friends who knew nothing about the project. When faced with a new conversation, they weren’t exactly sure how to speak to the model. Even if given the instructions, the User Interface (UI) should be designed to be intuitive of what the system is looking for.
Jailbroken Voting Machines
The facilitator can be jailbroken, with disastrous consequences.
In the majority of US elections in 2022, electronic voting remained the minority8. Cybersecurity experts still believe that online voting is rife with risks9. But Agora takes that one step further.
Assume for a moment that the infrastructure that enables Agora is secure (e.g. servers, users cannot be faked etc.). AI models, like the facilitator, are still trivial to jailbreak10. What if the facilitator gets jailbroken? Does that mean we can’t trust the statements they produce?
Serious work has to go into designing this system with those safety principals in mind.
Similar Work
OpenAI’s Democratic Inputs
The field of technological democratic inputs is not new. In 2023, OpenAI commissioned 10 experiments to explore how technologies, like ChatGPT, newly enabled novel forms of large-scale deliberation11 .
OpenAI released their key learnings12. They also found diversity of view points and reaching consensus were fundamentally at odds. Interestingly, they also found that public opinions can change drastically depending on their presentation. This exemplifies the dangers of having inconsistent model behaviours.
Tessler et al. (2024)
A recent Science study13 found that AI can be used to generate statements that reached consensus on controversial topics (including Brexit, climate change, immigration etc.). In fact, they found that it could do so better than human moderators.
However, the fundamental approach taken by Tessler et al. was different. They trained a language model to generate and refine statements that captured shared perspectives among participants. The AI iteratively improved these statements by incorporating critiques from participants, aiming to maximise endorsement from the users. By contrast, Agora takes the pure (albeit refined) statement from the user, and then tries to garner support from it.
Future Steps:
Agora requires further development to be practical. The hardest technical challenge is designing an appropriate backend and data structure to store ethical stances. It’s unclear what the data-structure would even look like. (The Meaning Alignment Institute, funded by AI, explored a “Moral Graph”14).
Additionally, once the we have discovered the stances these models should take, it’s unclear how to make them take that. It’s easier to fine-tune broad ideas during the supervised fine-tuning stage, but how do we do that for concrete behaviours? Or do we throw the lessons into system prompt? How would this scale?
These are technical problems, and thus (theoretically), solvable.
Ideally, once this the platform is fully developed, it would be hosted on every model provider’s websites. Users would be given the option to participate in deliberation whenever they choose. Model providers would then work on regularly incorporating the stances into their models.
Code:
The code for the prototype is hosted publicly on my GitHub, here.
System Prompt:
The following is the prompt the facilitator was given for collecting user statements.
<FACILITATOR_SUMMARY>
Agora: An AI system that acts as a NEUTRAL FACILITATOR in a large-scale deliberation/debate process. Many participants are engaged in complex discussions where they propose statements on controversial topics and try and gain concensus. Facilitator will NEVER insert its own opinions or viewpoints.
</FACILITATOR_SUMMARY>
<FACILITATOR_BEHAVIOR>
1. Facilitator will NEVER insert its own opinions or viewpoints. Facilitator avoids personal bias and refrains from judging participant viewpoints.
2. Facilitates the user by helping them tease out their true views on the topic.
3. Records a clear, concise, high entropy sentence summarising each of the user's views when they're fully formed.
4. Offers guidance if the user is uncertain, suggesting potential alternative angles.
5. If asked, Agora helps the user understand the debate landscape.
6. Facilitator will be provided with a list of pre-existing viewpoints and their support.
7. Be concise, high entropy and to the point.
8. Facilitator maintains a calm, respectful demeanor.
9. The facilitator can SUBMIT the user's statements for other participants to consider. Eventually, the user will be notified of how much support / agreement their statement received.
</FACILITATOR_BEHAVIOR>
<PROVIDED_DATA>
- Facilitator will be provided with a list of pre-existing viewpoints and their support.
</PROVIDED_DATA>
<FACILITATOR_STYLE>
- Be concise, high entropy and to the point.
- Use clear, neutral, and encouraging language.
- Presents data or percentages to illustrate agreement levels.
- Suggests refinements to proposed statements.
- If the user feels lost, suggest potential angles to consider.
- NEVER INTRODUCES PERSONAL BIASES / ITS OWN OPINIONS.
</FACILITATOR_STYLE>
Footnotes
-
Roth, Emma. “ChatGPT Now Has over 300 Million Weekly Users.” The Verge, 4 Dec. 2024, www.theverge.com/2024/12/4/24313097/chatgpt-300-million-weekly-users. ↩
-
Martineau, Kim. “What Is AI Alignment?” IBM Research, IBM, 8 Nov. 2023, research.ibm.com/blog/what-is-alignment-ai. ↩
-
Lu, Donna. “We Tried out DeepSeek. It Worked Well, until We Asked It about Tiananmen Square and Taiwan.” The Guardian, The Guardian, 28 Jan. 2025, www.theguardian.com/technology/2025/jan/28/we-tried-out-deepseek-it-works-well-until-we-asked-it-about-tiananmen-square-and-taiwan. ↩
-
Hinton, Lauren. “More than 18 Million Brits Have Used ChatGPT for Financial Advice or Would Consider Doing So.” FF News | Fintech Finance, 29 Aug. 2024, ffnews.com/newsarticle/fintech/more-than-18-million-brits-have-used-chatgpt-for-financial-advice-or-would-consider-doing-so/. ↩
-
Rozado, David. The Politics of AI an Evaluation of Political Preferences in Large Language Models from a European Perspective. 8 Oct. 2024. ↩
-
https://www.theverge.com/news/618109/grok-blocked-elon-musk-trump-misinformation ↩
-
Goñi, Iñaki. “Make It Make Sense: The Challenge of Data Analysis in Global Deliberation | Deliberative Democracy Digest.” Publicdeliberation.net, 2024, www.publicdeliberation.net/make-it-make-sense-the-challenge-of-data-analysis-in-global-deliberation/. ↩
-
Zdun, Matt. “Machine Politics: How America Casts and Counts Its Votes.” Reuters, 23 Aug. 2022, www.reuters.com/graphics/USA-ELECTION/VOTING/mypmnewdlvr/. ↩
-
Parks, Miles. “Voting Online Is Very Risky. But Hundreds of Thousands of People Are Already Doing It.” NPR, 7 Sept. 2023, www.npr.org/2023/09/07/1192723913/internet-voting-explainer. ↩
-
Rajkumar, Radhika. “Deepseek’s AI Model Proves Easy to Jailbreak - and Worse.” ZDNET, 31 Jan. 2025, www.zdnet.com/article/deepseeks-ai-model-proves-easy-to-jailbreak-and-worse/. ↩
-
OpenAI. “Democratic Inputs to AI.” Openai.com, 2023, openai.com/index/democratic-inputs-to-ai/. ↩
-
OpenAI. “Democratic Inputs to AI Grant Program: Lessons Learned and Implementation Plans.” Openai.com, 2024, openai.com/index/democratic-inputs-to-ai-grant-program-update/. ↩
-
Tessler, Michael Henry, et al. “AI Can Help Humans Find Common Ground in Democratic Deliberation.” Science, vol. 386, no. 6719, 18 Oct. 2024, https://doi.org/10.1126/science.adq2852. ↩
-
Edelman, Joe, and Oliver Klingefjord. “OpenAI X DFT: The First Moral Graph.” Substack.com, Meaning Alignment Institute, 24 Oct. 2023, meaningalignment.substack.com/p/the-first-moral-graph. ↩