What:
The best sequence of tokens in a Language is not necessarily picking the best token at each step. We can do beam search to find it.
- Here, we’ve got a beam of 2.
- The higher the beam, the more branches we’re searching - the more computationally hard.
- The lower, the worse the searching actually is (no guarantee to being close to the global optima).
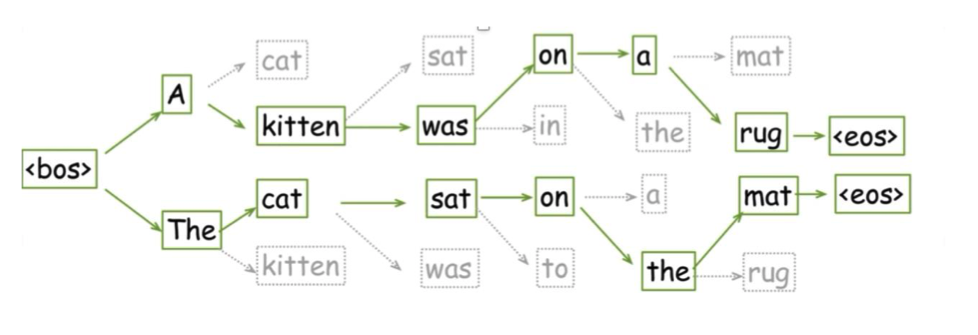
We tend to use this (as opposed to sampling) for non-deterministic stuff. E.g. language translation.