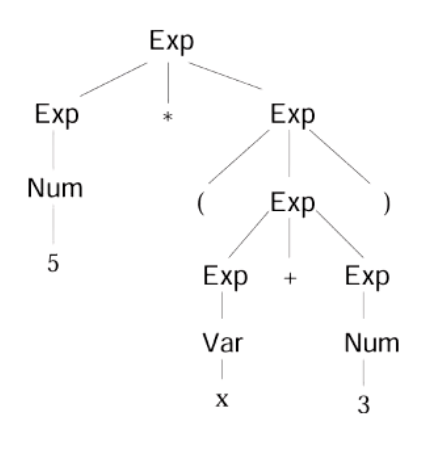
What?
It’s a part of the Compiler Frontend that constructs an abstract-syntax tree and detects if the tree is valid (e.g. missing semicolon). I.E. It creates the following tree:
Types of parsers:

Top Down Parser
Build an AST by working from the start symbol to the input sentence. The decision you have to make is which rule of reduction should you use?
Caveats:
The context-free grammar must not have:
- Left-Recursion (any terminal in a rule must be at the far right of the equation)
- Non-determinism (i.e. ambiguity)
Recursive Descent Parsers:
Conceptually:
- Define each (non-terminal) rule as a function.
- Recursively step down through each character.
- After each successful function, fill in the program’s tree.
- You’ll find that you naturally it fill recursively from the left.
- The resulting tree is close to the grammar’s tree.

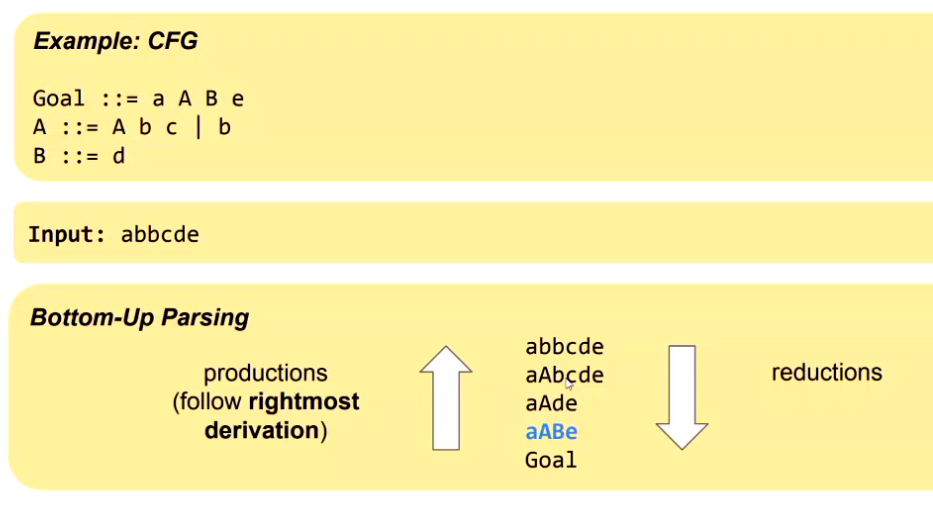
Bottom Up Parser
Builds an AST by working from the input sentence BACK to the start symbol.
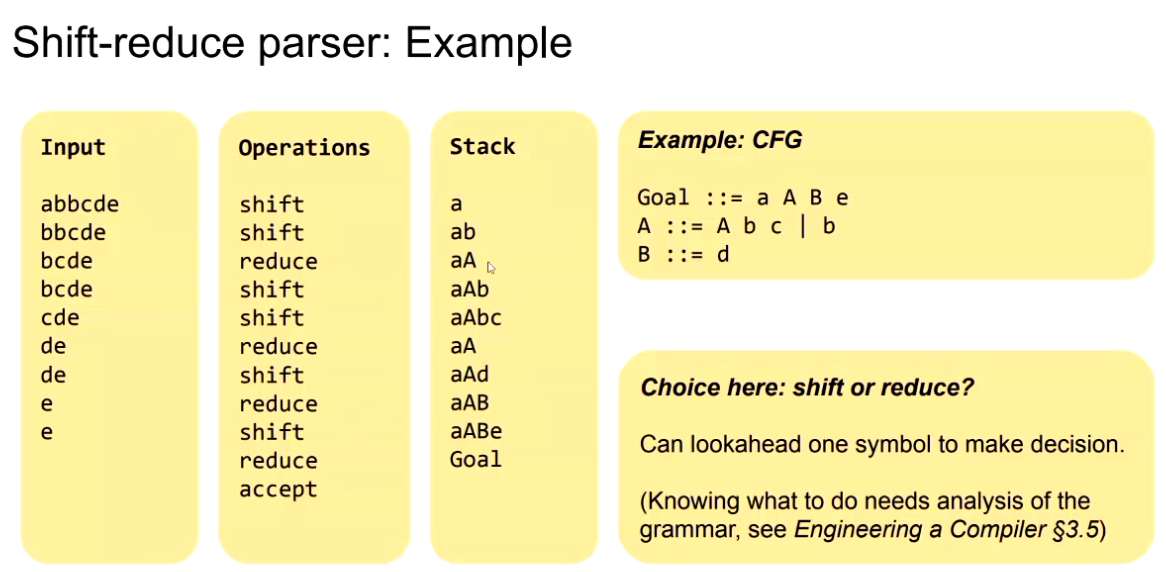
Shift Reduce Parser Algorithm:
A Shift-Reduce Parser is a bottom-up parser that processes input symbols using a stack. Derives the input string from the start symbol of the grammar.
Four Actions in Shift-Reduce Parsing
- Shift: Moves the next input symbol onto the stack.
- Reduce: Replaces a sequence of symbols on the stack with a non-terminal based on a grammar rule.
- Accept: Signals successful parsing when the stack contains the start symbol and input is empty.
- Error: Reports an error if no valid parsing action exists.
How does the parser know when to shift or reduce?
Similarly to the top-down parser, can back-track if wrong decision made or try to look ahead.
Can build a DFA to decide when to shift or to reduce.