What?
It’s about taking a sentence and assigning each word into grammatical categories.
E.g.as
The → Determiner (DET)
quick → Adjective (ADJ)
brown → Adjective (ADJ)
fox → Noun (NOUN)
Approaches To POS Tagging:
- Rule-Based Tagging: Uses rules / dictionaries to come up with them
- Probabilistic Tagging: Uses Hidden Markov Models (HMM) , Probabilistic Finite State Machine etc.
- Deep Learning Tagging: Uses RNNs, LSTMs, etc. to come up with them.
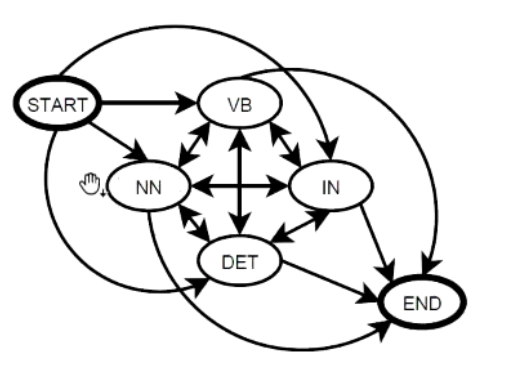
Note on Probabilistic FSM:
This is a really cool way of thinking about it. You ideally want to fine-tune the probabilities of, given being on one state, going to another state.
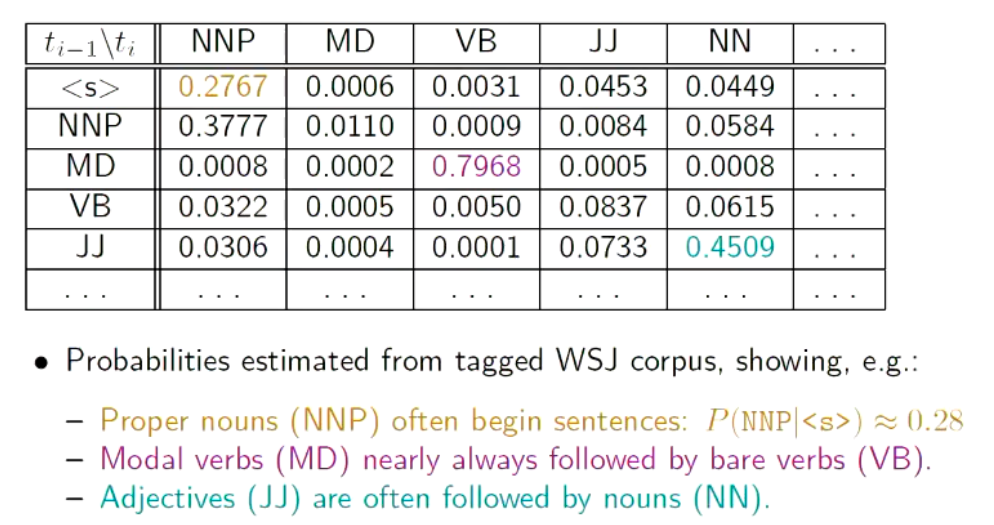
There’s a dataset where each word has a probability of a corresponding category. If we take every word’s category in our sentence, and multiply their probabilities, then the result is the probability of that sentence.
The Parts of Speech:
- Open Class Words: Content words
- Nouns, verbs, adjectives, adverbs
- Content-bearing: refer to features of the world
- It’s open as there’s no limit to these words (and new ones are constantly added: email!)
- Closed Class Words: Functional Words (“Syntactic Glue”)
- Pronouns, prepositions, connectives etc.
- Limited amount
- The ties the concepts of a sentence together.
Challenges:
- Ambiguity: Water the plants vs the water on the plants.
- Verb or noun?
- Sparse Data: We’ve not seen all of the data in all contexts before.