This is hard
Take the MMLU (ik irrelevant). Anthropic said that small changes like changing the options from “(A)” to “(1)” etc. could have ~ change in accuracy. Or that promising it $300k for a good job means it does better. How do you then evaluate these models scientifically?
Hisham's Extreme Example:
While working as an engineer with these models, Hisham’s team discovered that the order of the correct answers on the MMLU mattered a lot. For example, if you moved the correct answer to be A every single time, the models accuracy would drop to (random). Move every answer to D and accuracy would shoot up to . Additionally, every model performed differently to each lettering placement.
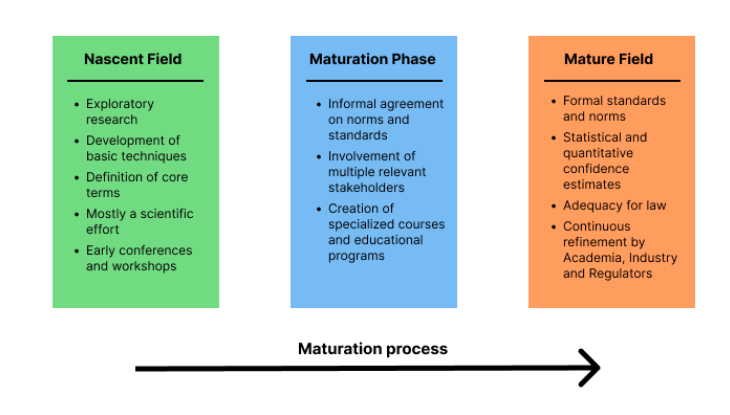
Maturation of Evaluations:
All fields undergo maturation. Only when it’s most mature, do we get normals and standards (think of shoe-making from ShoeDog - originally anything that covered their feet went and now they undergo battery of tests).
Problems With Benchmarks?
- What do we even measure?
- If we benchmark our models on “harmlessness”, how do we benchmark for that, across the whole definition of it? If they no longer allow you to cook meth, but encourage you to be racist, then clearly the benchmark needs work.
- How do we quantify the benchmark, especially for natural language?
- Measuring average-case vs worst case?
- Can we trust our results?
- Even if we reworded the prompt entirely, would we still get the same result from our benchmarks?
- How do we measure bias?
- Can we come up with a hypothesis and estimate statistical significance?