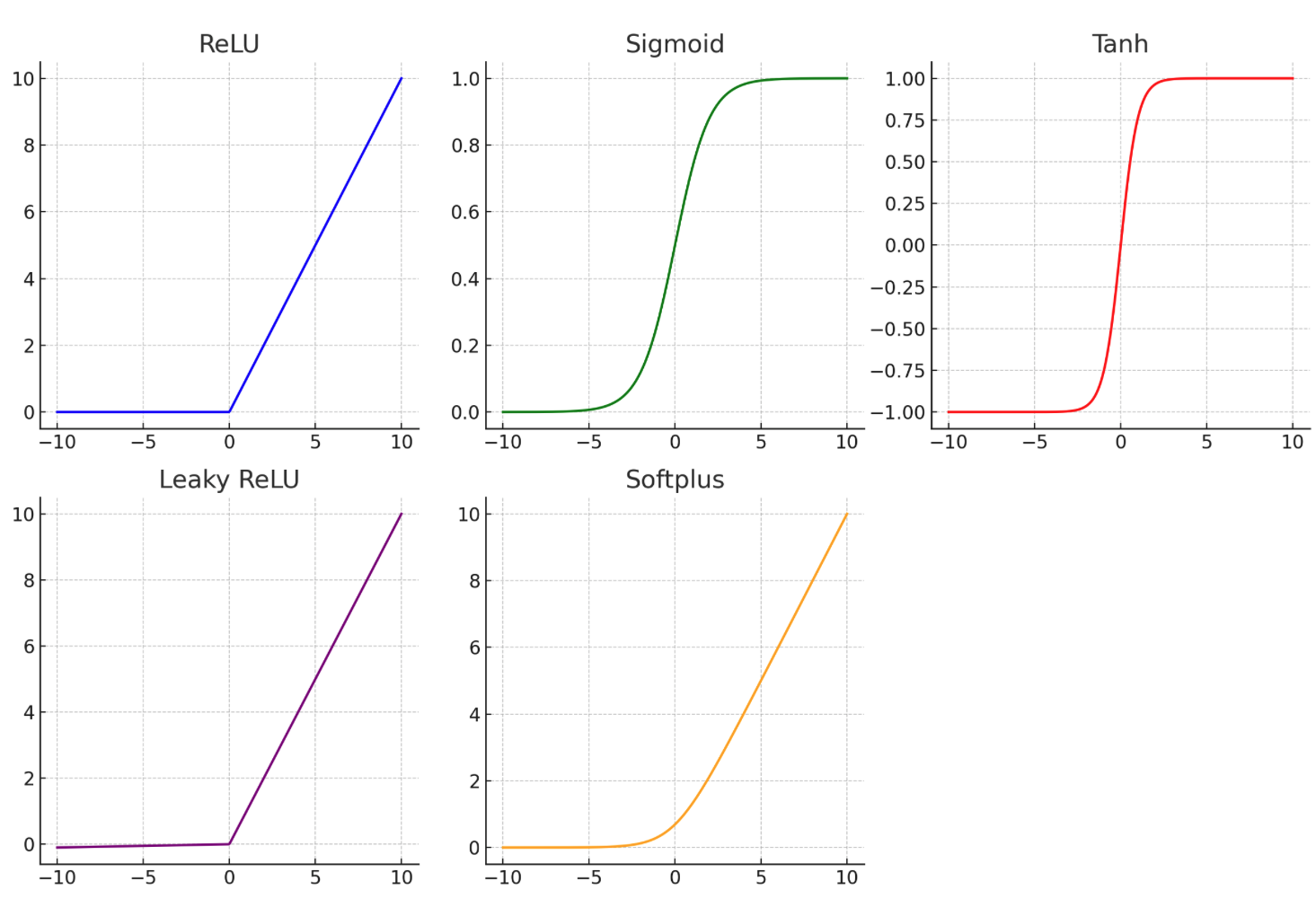
Outputs 0 for negative values, and grows linearly for positive ones.
Encourages sparse activations.
Simple, efficient, and widely used.
Downside: can cause “dead neurons” (always output 0).
2. Sigmoid
f(x)=1+e−x1
Squashes input into (0, 1) range.
Useful for binary classification.
Can cause vanishing gradients in deep networks due to saturation at extremes.
3. Tanh (Hyperbolic Tangent)
f(x)=tanh(x)
Outputs range from -1 to 1 (zero-centered).
Still suffers from vanishing gradient problem.
Often used in older architectures like RNNs.
4. Leaky ReLU
x & \text{if } x > 0 \\
0.01x & \text{otherwise}
\end{cases}$$
- Fixes ReLU’s "dying neuron" issue by allowing a small gradient for negative inputs.
- Maintains sparsity but avoids total shutdown of some neurons.
### **5. Softplus**
$$f(x) = \log(1 + e^x)$$
- A **smooth approximation of ReLU**.
- Always has a positive gradient, so no dead neurons.
- More computationally expensive than ReLU.
### **6. [[Softmax Function]]**:
It's in the link.
## What's the point with activation functions?
Take the simple, 2 class [[Logistic Regression]] formula, but without the sigmoid (so just $w \cdot x + b$). No matter how many ways you combine multiple neurons together, you'll always end up with a linear function (i.e. a straight line). *This is known as linearity.* (Only possibility in single-layer network)
But when you combine them with an activation function (i.e. non-linear functions), e.g. sigmoid, you introduce non-linearity. Non-linear functions are far more powerful than a single dividing line on a plane.
> ***Universal Approximation Theorem:*** Any two-layer network (one input layer, one hidden layer) with a non-linear activation function and a sufficient number of hidden units can ***approximate any continuous function***.