Intuition
What:
Neural Networks refers to an entire category of AI models loosely inspired by the brain. The callout above is a pretty good intuition (credit Pierre Mackenzie!).
Components of a Neural Network:
The Neuron:
A fundamental building block of a NN is the Neuron. Like the human brain, they take an input and, based on the strength of it’s connections, it will fire a signal of specific strength forwards. (The strength of it’s connections are learned / honed from experience).
When you put a whole collection of them together (i.e. network or brain), emergent properties arise (i.e. ability to ability to walk etc.).
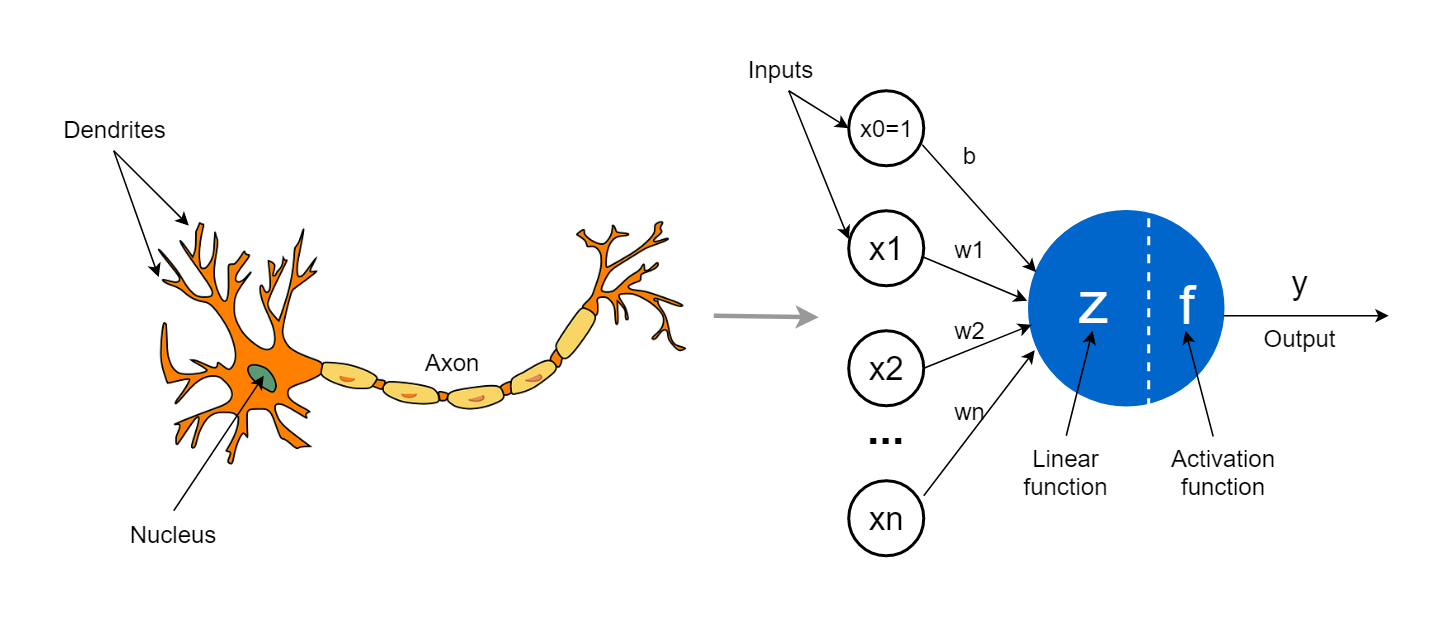
The Neuron, Dissected:
- The neuron has a bunch of inputs ().
- Each has a corresponding connection (i.e. weight) connecting it to the neuron.
- Each neuron also has a bias number. (Helps ensure the model can learn something of value, even when the inputs are )
- The “Linear Function” is literally just computing the weighted sum of the inputs (and the bias!).
- The linear function () is calculated by:
- The “Activation Function” (e.g. ReLU, Sigmoid, Softmax etc.). allows us to learn non-linearity. If we didn’t have that, our decision boundaries could not have curves.
Fun Fact!
A Neural Network with single linear layer (and no activation function) is called The Perceptron. When they were first invented ~70’s, they were considered the absolute state of the art. Unfortunately, they sucked at learning basically anything.
It’s only been more recently that we’ve had the compute and data to scale a bunch more layers. Doing this (Deep Learning) has allowed us to truly get value from them.
How Do They Learn?
Take the following Neural Network, it’s got 784 inputs, 2 hidden layers, and 10 outputs.:
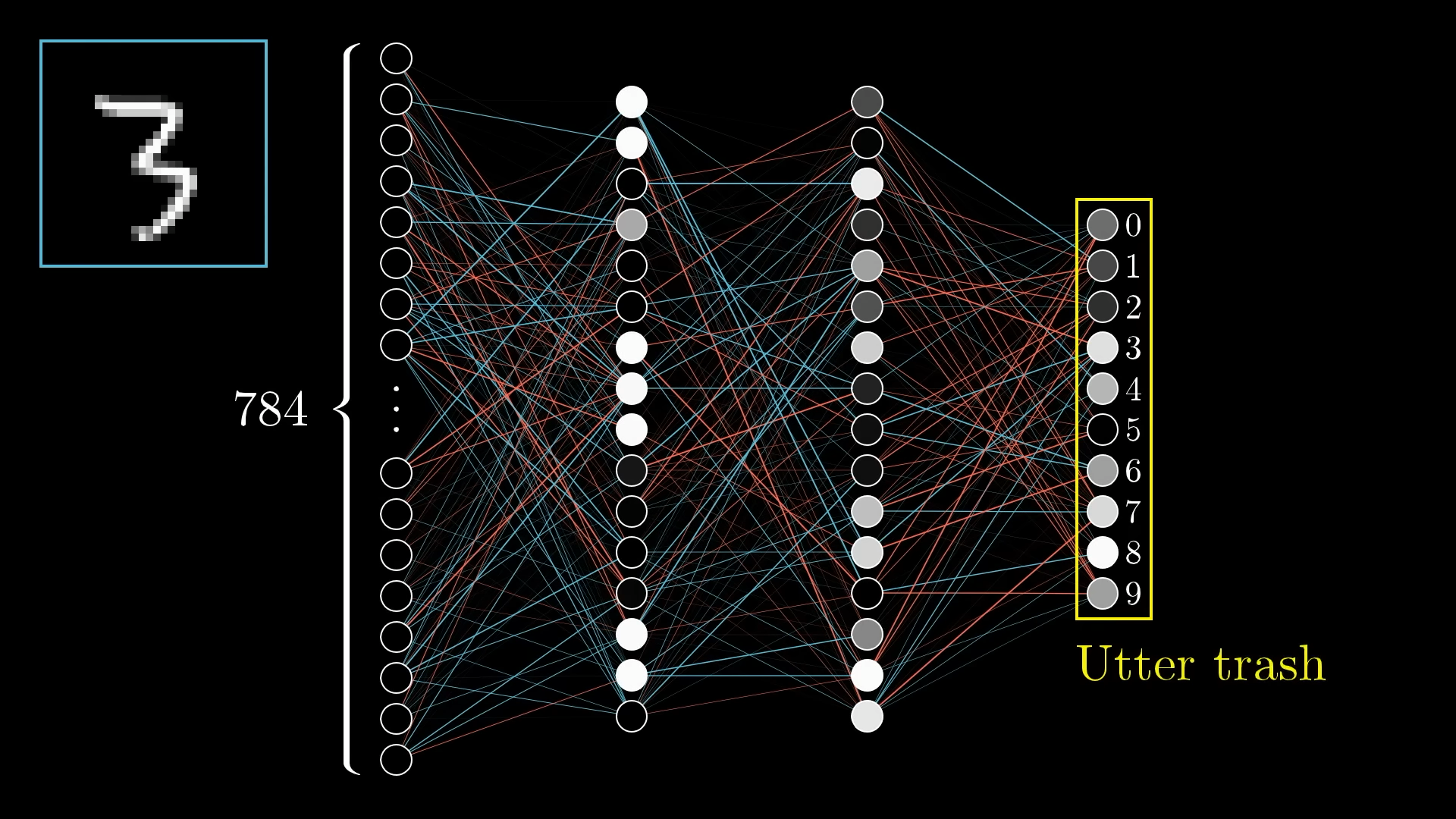
Training, at a super high level:
- Choose the hyperparameters (architecture and optimiser)
- Initialise the model (randomly)
- Optimise the model with Gradient Descent. (Click for wayyyy more details)
(a) Sample an input–label pair from the data
(b) Perform a forward pass to obtain a prediction
(c) Calculate the loss (Cross-Entropy Loss) between the prediction and the label
(d) Back-propagate to get the gradient of the loss wrt parameters
(e) Parameter update
Types of Neural Networks:
-
Feedforward Neural Networks (FNNs):
- The simplest type, where information flows in one direction (from input to output).
- Multilayer Perceptrons (MLPs) are a type of feedforward neural network with one or more hidden layers.
- MLPs are fully connected, meaning every node in one layer is connected to every node in the next layer.
-
Convolutional Neural Networks (CNNs):
- Specialised for tasks like image recognition and processing.
- They use convolutional layers that apply filters to detect features (like edges, shapes, and patterns).
-
Recurrent Neural Networks (RNN) (RNNs):
- Designed for sequence-based data like time series or language models.
- RNNs have connections that form directed cycles, enabling them to have “memory” of previous inputs.
-
Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs):
- These are more advanced forms used for generative tasks (e.g., creating new images, enhancing photos).
-
- A more recent and powerful architecture for Natural Language Processing (NLP) and computer vision.
- The Transformer architecture underlies many state-of-the-art models (e.g., GPT and BERT).
- It’s phenomenal, thanks to attention
And many many more!