What:
A type of neural network that handles sequential data by keeping memory of past information. They do this with a feedback loop in its hidden layers. This allows information to persist across time steps. Thus, it’s really good for time series data. (A Seq2Seq model).
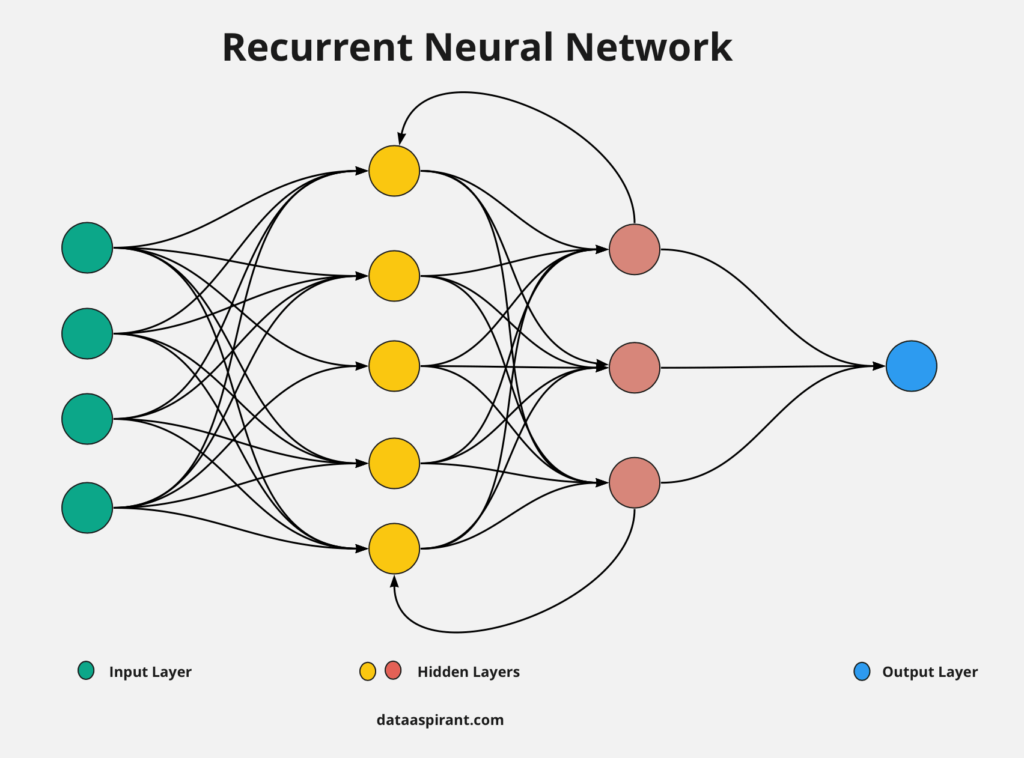
How:
- Simply: There’s a hidden state that stores information about previous inputs (i.e. compressed understanding of history) and is updated at each time step.
- Formula: h_t = f(W_h h_{t-1} + W_x x_t + b_h)$$$$y_t = g(W_y h_t + b_y)where:
- = hidden state at time
- = input at time
- = output at time
- = weight matrices
- = biases
- = activation functions (commonly tanh or ReLU for , and softmax for )
Visually:
You can visualise an RNN with a loop that feeds back on itself like this.
- You feed the very first input.
- Once you get to the RELU stage, you pass that information back to the weight leading into you (instead of continuing onto the output like a normal neural network).
- You then feed in the next input through the model.
- This gets summed with the previous example.
- Once you’ve hit the last input, you can continue onto the prediction.
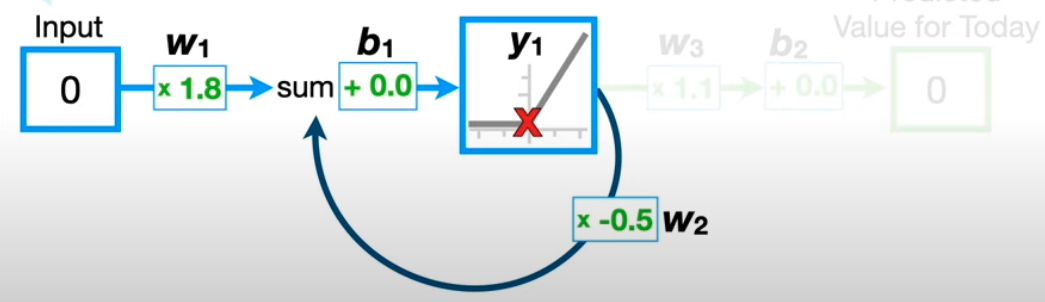
But…
A much simpler example to view this would be by unwinding the Neural Network like this (for a series of 3 inputs.)
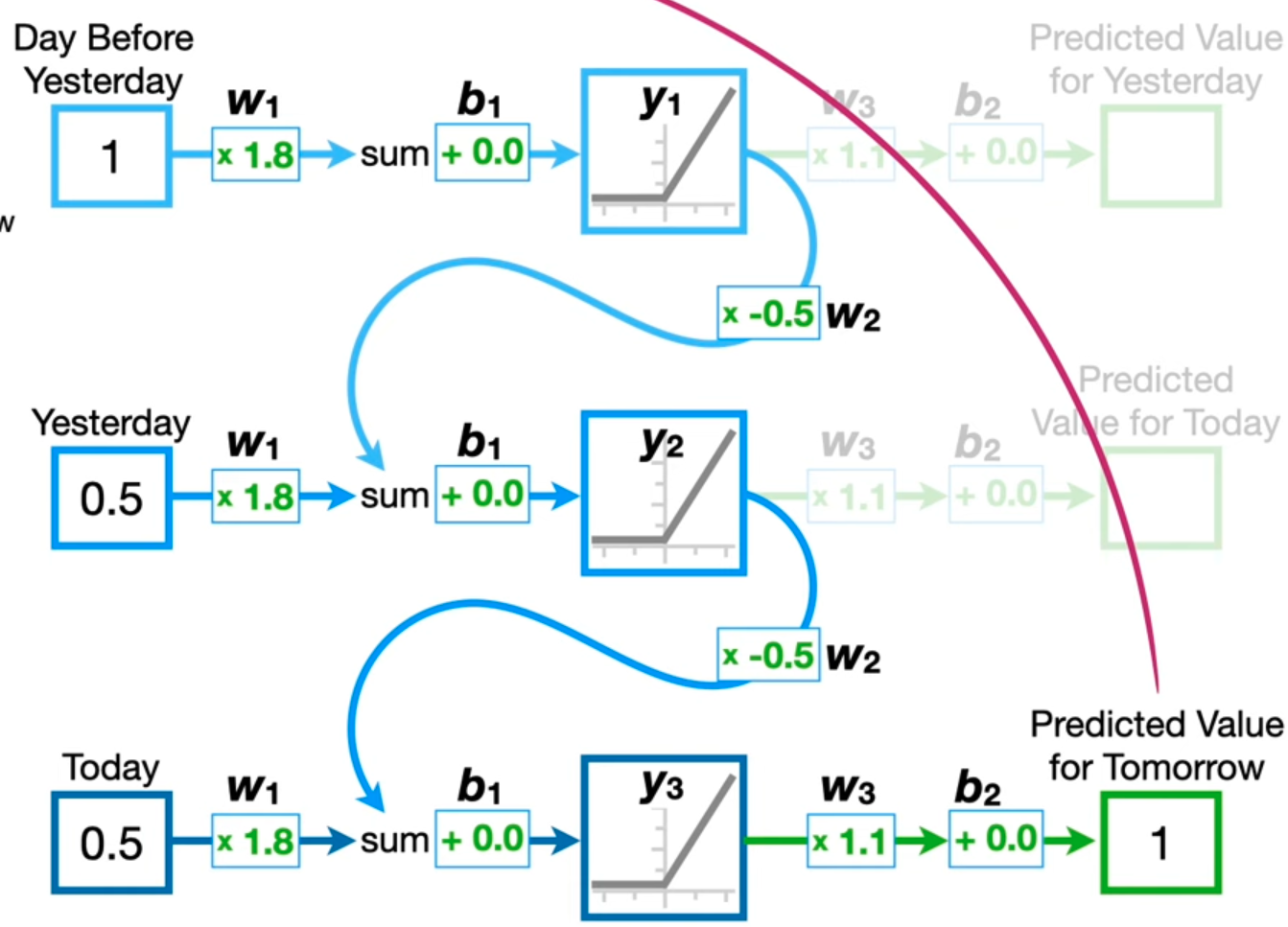
Note, in this, the weights and biases are shared amongst every input.
Problems:
- Vanishing Gradient Problem: When training deep RNNs, gradients shrink over long sequences, making it hard to learn long-term dependencies / contexts.
- One of the ways to get around this is to create “residual” or “highway” connections. You add a connection that goes straight from the input to the output, as well as going through the block. That way, even if it’s forgotten, it comes back!

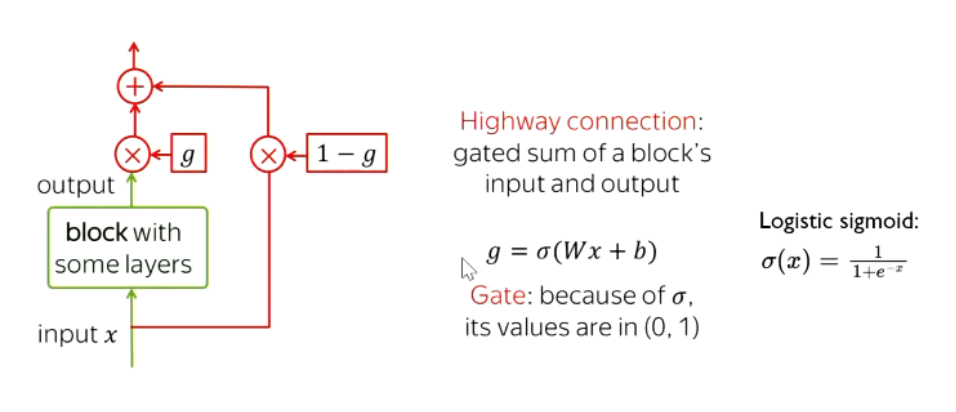
- This is the basis of LSTMs!
- Not parallelisable. If deep learning has taught us anything, it’s that we should parallelise everything!
Architecture:
In case it wasn’t obvious, the RNN is an Encoder-Decoder model.
Bidirectional RNNs:
An RNN that processes sequences in both directions - left to right and right to left.