What:
It’s a family of 2-part Neural Network architectures:
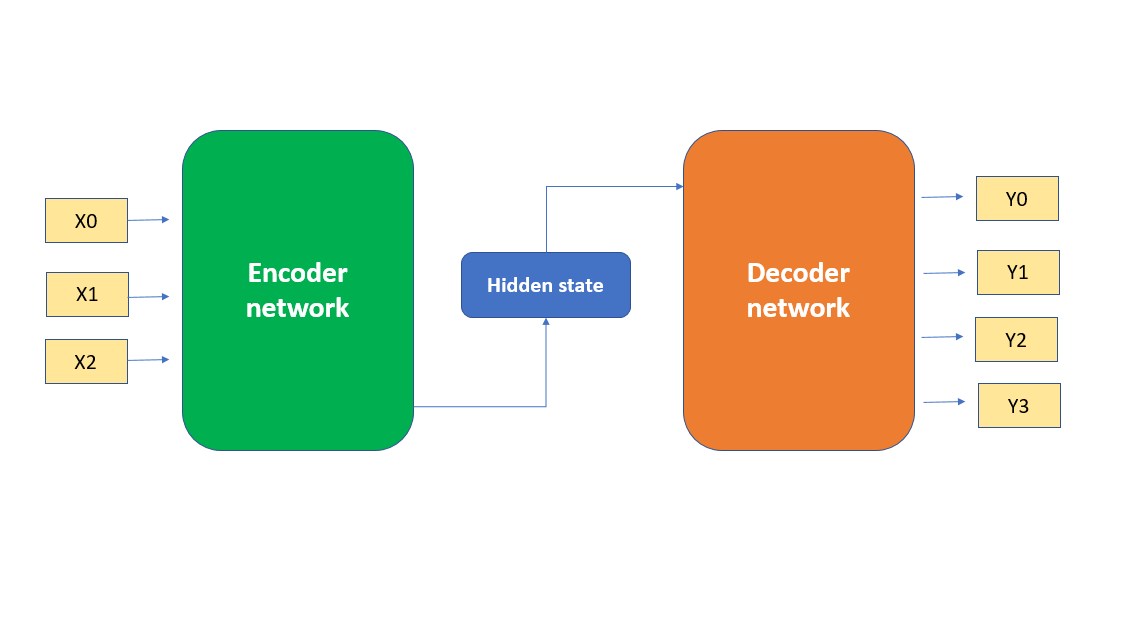
- You take input data and pass it into an encoder network.
- The encoder turns it into some latent representation (i.e. compressed vector(s) that represent the input)
- You then pass that hidden state into a decoder network, which transforms it into the output.
E.g. It would be like passing English text into the encoder, it’s transformed into the abstract, compressed meaning of the sentence, and then the decoder model transforms that into a French sentence.
Cross-Attention:
In normal attention, the model attends to itself. So a sequence like “the lazy dog”, “lazy” would attend heavily to dog, but not so much “the”.
But cross attention, you work by attending across the network. So the decoder’s sequence may attend to the encoder’s sequence to decide what information to focus on. It’s essential for tasks where input and output are different sequences.
Encoder Only 🆚 Decoder Only 🆚 Encoder-Decoders Learning Styles:
- Encoder only: Masks certain words, and then predict the missing one. (It’s auto-encodes, the input). (Synonymous to Auto-Encoder)
- Decoder only: Auto-regressively decodes the input into the output. (ChatGPT) (Synonymous to Auto-Regressive Encoders)
- The output is simply the input, shifted by 1. Then, you’ve gotta predict the final output.
- It’s only self-attention
- E-D: Uses MLM and corrupts multiple sequences at a time. (Seq2Seq)
Types of Encoder-Decoders:
- Recurrent Neural Networks (RNN)
- The original Transformer