Goal Of Attention:
Words have different meaning depending on the context (i.e. “Make a deposit at the bank” vs. “The river bank”). But with traditional Vector Embeddings (and after the first step of an LLM), the “bank” embedding will be identical.
Ideally, an “Attention Block” will change (i.e. add/subtract to) those individual word vectors, so they (the vectors signifying the meaning of a word) move to a more accurate position (i.e. a position more reflective of its actual meaning).
Example:
Take the “monster” vector. It’s not very descriptive of anything in particular (other than an abstract, scary large and looming figure). Now take the sentence: “The green, 1-eyed creature is the star of the Disney Pixar movie. He’s short, has small horns and a non-confrontational figure. He’s not a very menacing monster.”. Ideally, the second instance of “monster” is incredibly close to the vector for “Mike Wazowski”.
Exactly how did we update the word’s vector? Well that’s what the Attention Mechanism does.
How Do We Actually Do It?
1. What Words Relevant?
We need to find out what words are important relative to other words. That is to say, when looking at 1 word, what word (that is previously before it) should we pay attention to?
1.1. Queries:
- Motivation: We want words to attend to only a specific selection of others in a sentence. Query vectors help us find out what to pay attention to.
- How Should They Work?: The query vector should be a vector that (somehow) encodes a question (or query 😉). For example, the word monster from above may have a query asking “What adjectives are describing me?”
- How Do We Get Query Vectors?: We’ll call the query vector of the -th word . To find it, we multiply the word embedding, (), by a learned matrix .
- Intuition: The query vector is the “search” query.
1.2. Keys:
- Intuition: (Ideally) These vectors (somehow) describe themselves. For example, “I describe the monster in question.”
- How They’re Learned: They’re made the exact same way as , but this time represented as .
1.3. Query:Key Matrix:
By getting the dot product of every Query Vector with every other Key Vector, we can see how much each word “attends to” every other word. We then apply softmax, column by column. In the below example, “fluffy” and “blue” attends to “creature”, and “verdant” attends to “forest”. (Size of the dot represents positive magnitude of softmax’ed dot product).
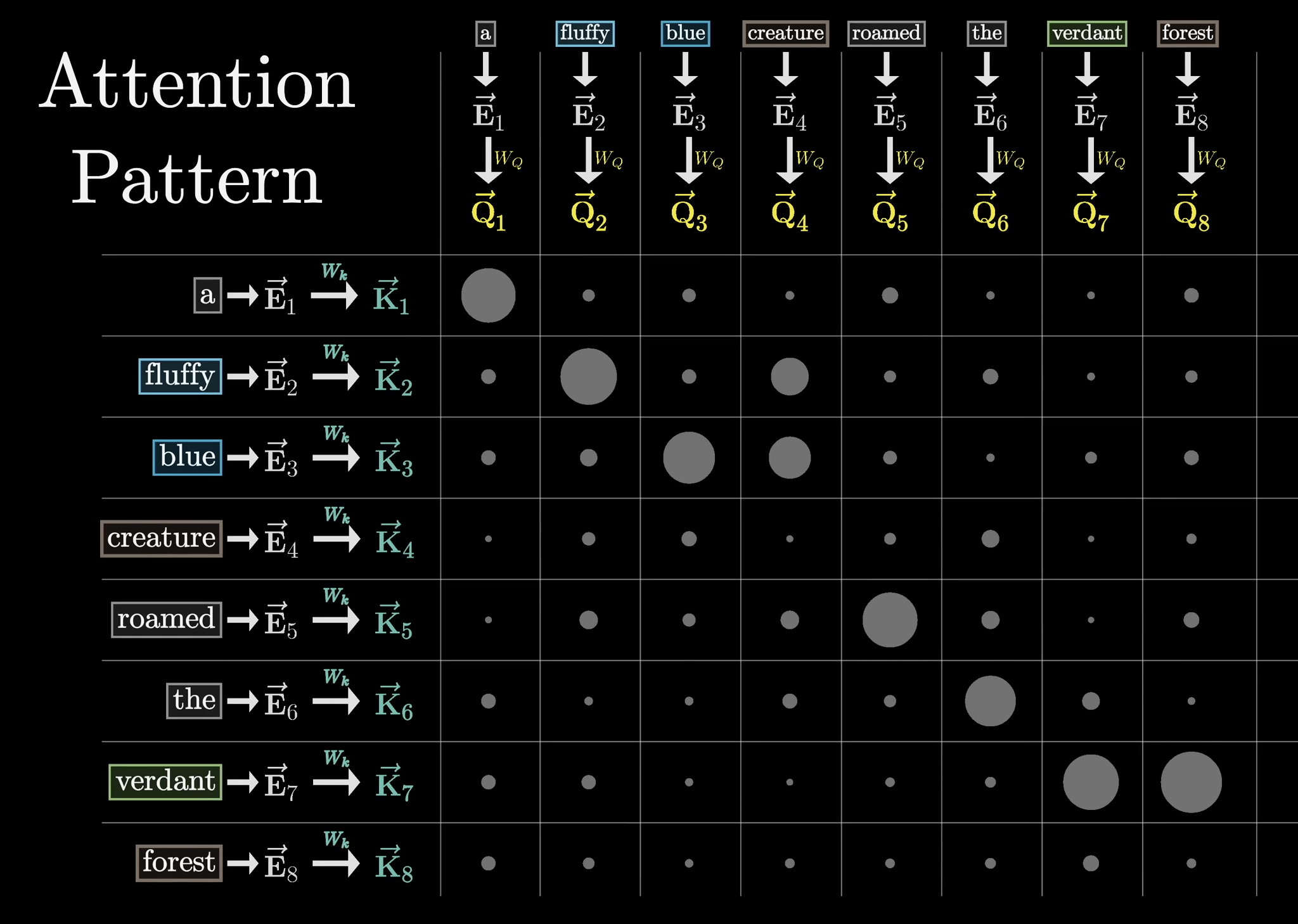
Note: To prevent later tokens influencing earlier ones, we set the values (pre-softmax) to the bottom left triangle to , so the resulting softmax. This is known as “Masking”.
Note 2: The size of the attention pattern is what’s commonly referred to as the context window. That’s why it was hard to just keep increasing the context window (with the original transformer architecture).
2. Updating Values
Great! We’ve found out how every word is relevant to every other word. Now, we need to work on updating those words’ embeddings (as we gave in the original Mike Wazowski example).
2.1. Value Matrix:
- Let’s say we want to update the vector for “monster” .
- We make another learnable Matrix, .
- We multiply this by every word’s embedding () to create .
- Multiply by the amount we need to attend to it by (i.e. by the size of dot product).
- Add the column up. The change () is the amount the word’s vector must change to represent it.
- Then add the change () to the actual word’s embedding (). Your new vector should be more contextually rich.
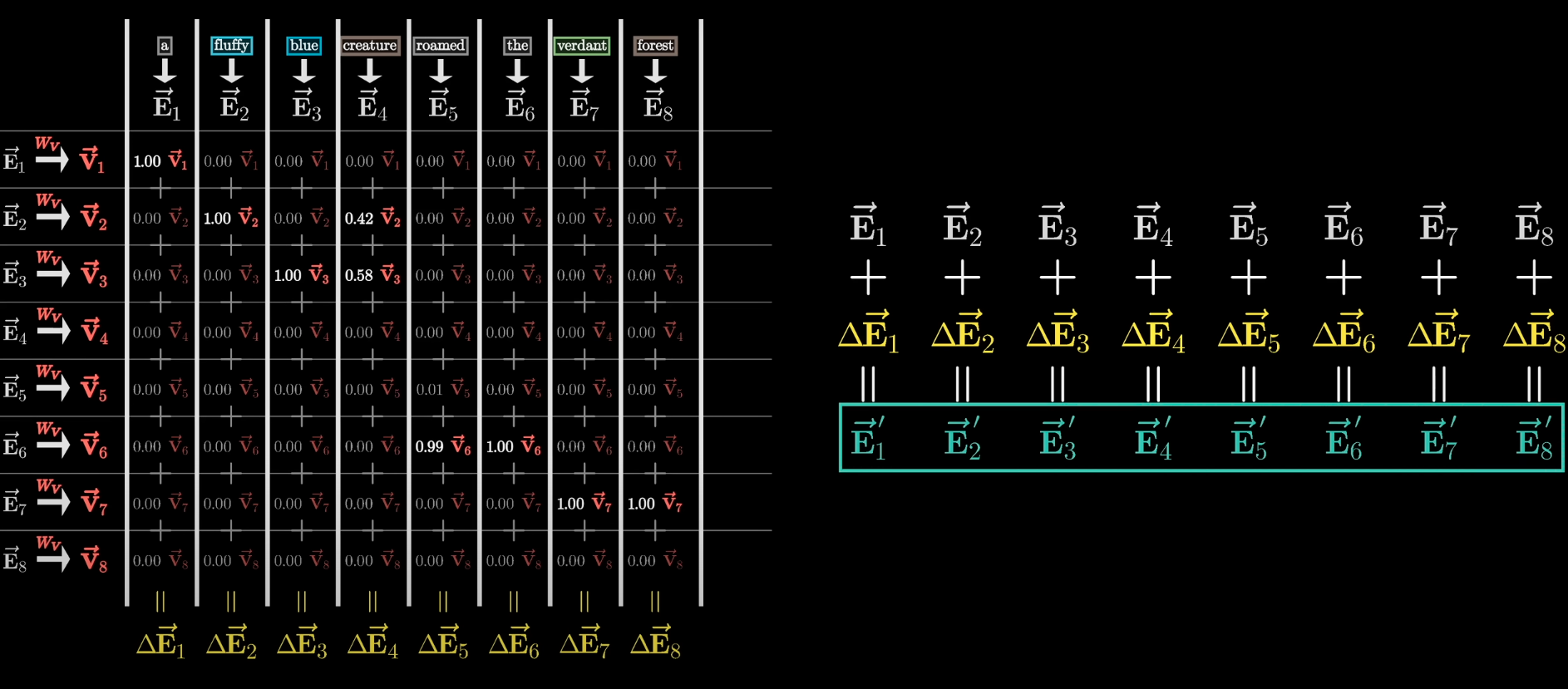
All of this combined is a single head of attention.
3. Putting It All Together:
We actually run a bunch of heads of attention in parallel (so multiple of the above images in parallel). They all just learn different , , .
- Each attention head proposes a change for a specific word’s embedding, so we add all of THOSE proposed changes to a word’s embedding. That’s just the updated word embedding for a single word. You’ve gotta do that for every word. No wonder these things use a lot of electricity.