What does it mean for words to be similar?
Time for some big brain moments right here. Imagine I asked you the following: Are the words “cat” and “dog” similar? Why? And how can you quantifiably prove this?
The words, lexicographically, are not similar at all (Bar they’re both 3 letters. But so is “bus”). But we intuitively know they’re similar. Cue the following idea:
Semantic Similarity / Harris Distributional Hypothesis:
Words are similar if they’re consistently used in similar contexts. ‘Cat’ and ‘Dog’, when taken in a large enough corpus, are consistently used around words like ‘cute’, ‘pet’ etc..
Representing Mathematically:
Ok. How do we represent that mathematically? We embed each word as a vector. We would hope that for words that are similar to each other, their corresponding vectors are close to each other in vector-space. Each dimension in the vector-space (would hopefully) correspond to some semantic meaning (e.g. gender or cities of countries - see “Gangsta shiii” section below).
Vector Embeddings are the corresponding vectors for a given word. An embedding matrix is essentially a Hash Table, where a word (token) has a corresponding vector.
Measuring Word Similarity:
General:
This is basic algebra - the multiple ways to tell if a vector is similar to another. Cosine similar tends to be the best.
Cosine Angle Between x and y:
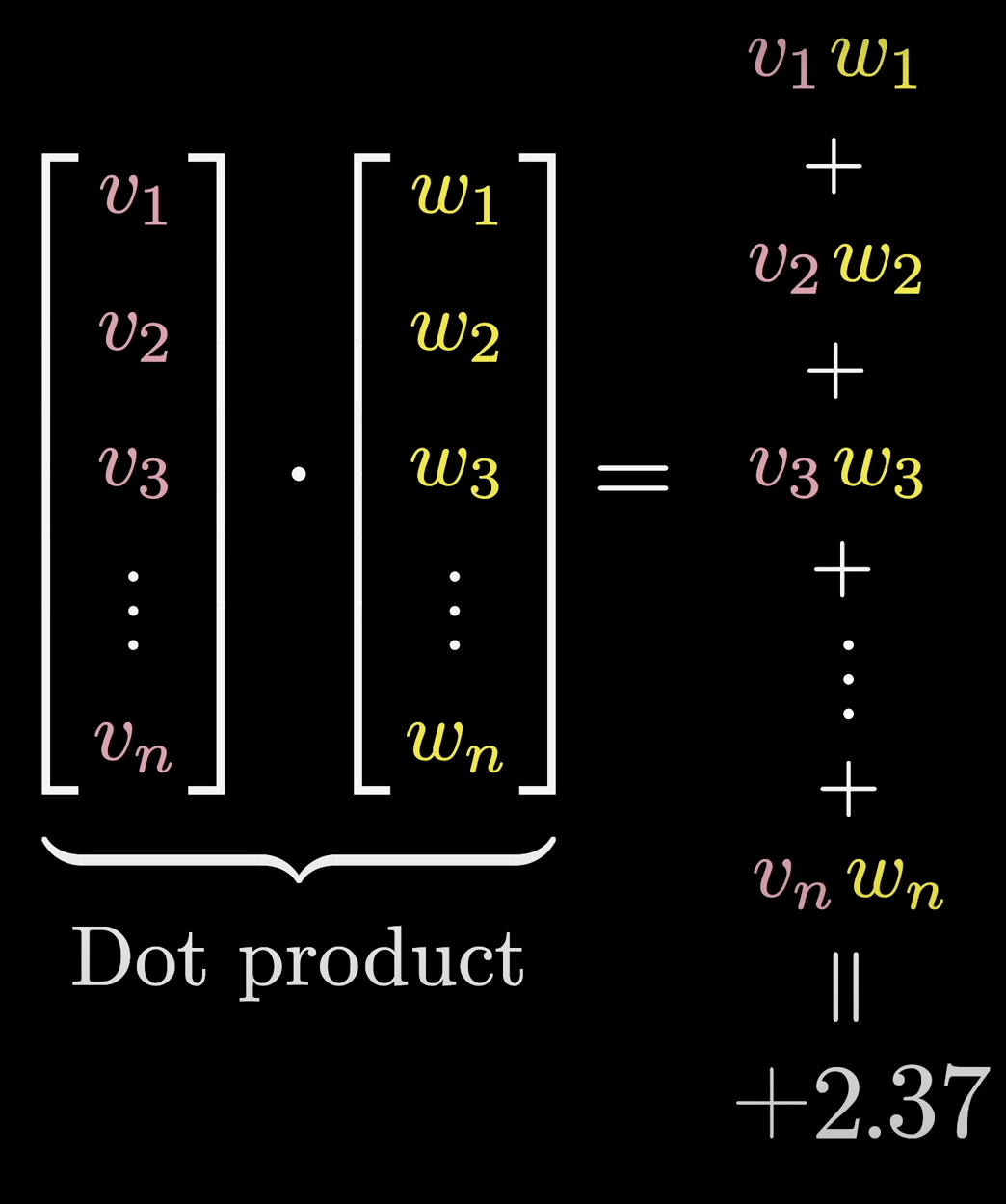
Dot Product:
Convenient because it looks like weighted sums again (efficient in GPUs). The Dot Product will be high if they’re similar, and low if they’re not.
Learning The Vectors:
There’s a couple ways, but Word2Vec is popular for a reason.
Some really cool gangsta shiii:
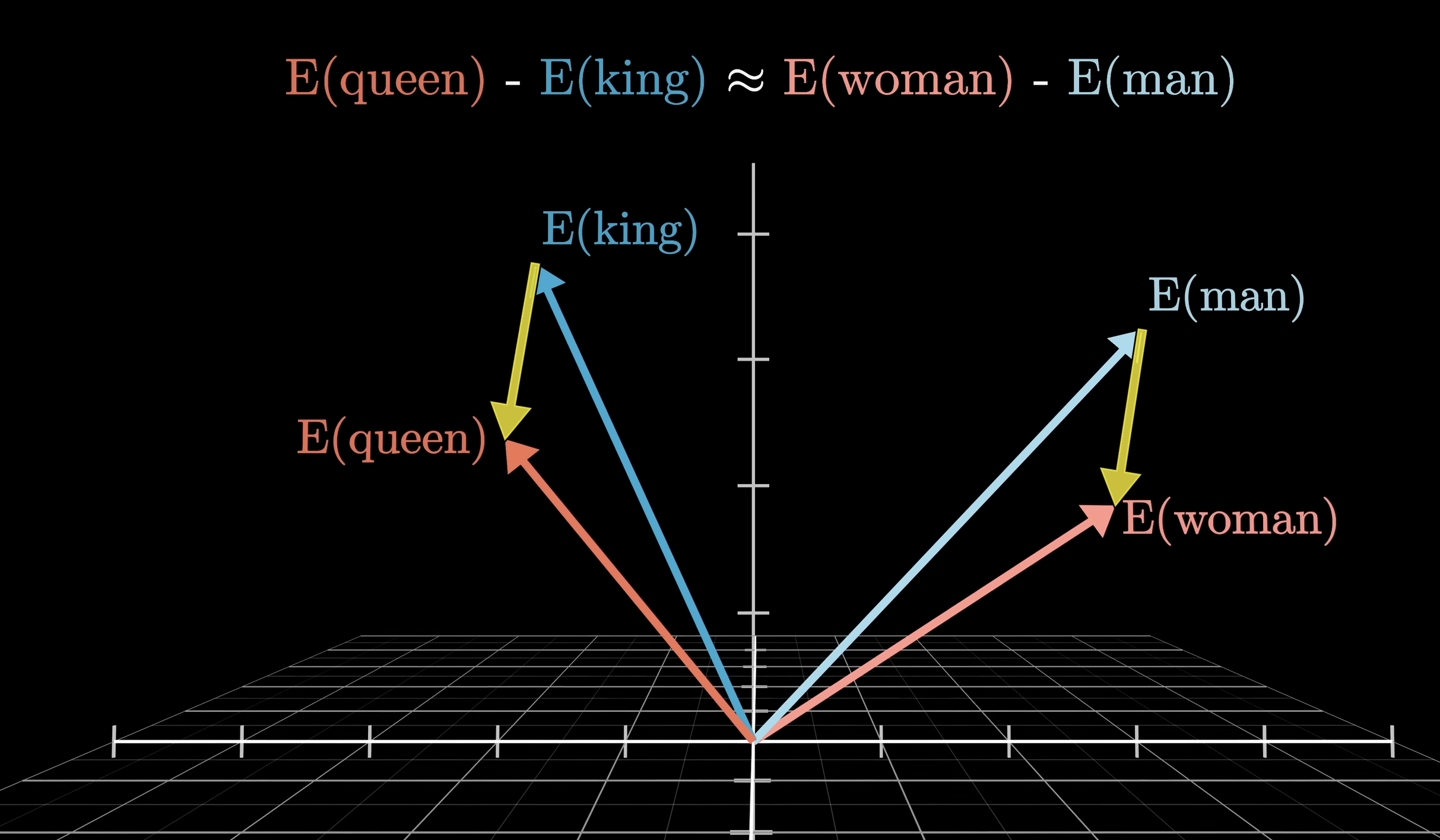
Dimensions can encode meaning:
Take the vector for ‘King’, subtract the vector for ‘Man’, add the vector for ‘Woman’ and call your resultant vector . The word in the nearest vector space to should be (if using a properly-trained vector embedding algorithm): ‘Queen’. In other words, the model found it advantageous to encode “gender” as a direction in the space.
Other Applications:
Vector encodings is how Google Reverse Image search works. If you split specific bits of an image up into vectors, similar images will be ones where there’s lots of nearby vectors.
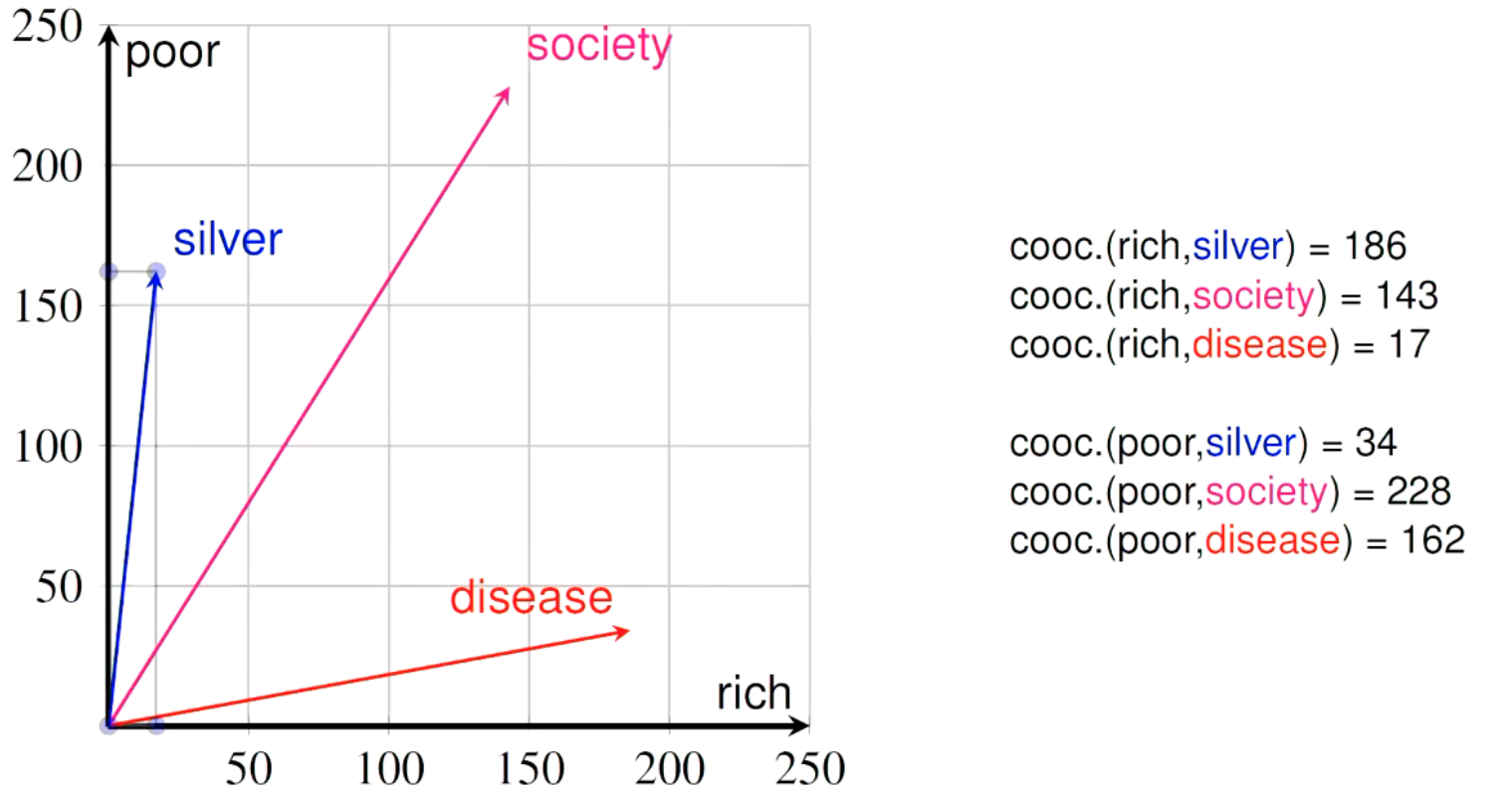
Definition of Semantic Similarity:
We use the Cooccurrence Count. It’s the amount of times that words w_1 and w_2 occur in the same corpus. The below is cooccurrence within 10 words in Wikipedia. Now we have the basis of the embeddings above.