What are they all about?
The easiest way to think of them is like a Python Dictionary. (In fact, in Python, they’re coded using Hash Tables). In other words:
- A collection of Key:Value pairs. Keys cannot appear more than once.
- They can be of any type.
The Keys are hella Techy:
Smart people made ways of accessing them by keys super efficient. It works as follows:
- A hash table is initialised, with a bunch of empty slots (boxes where data and its corresponding values will go).
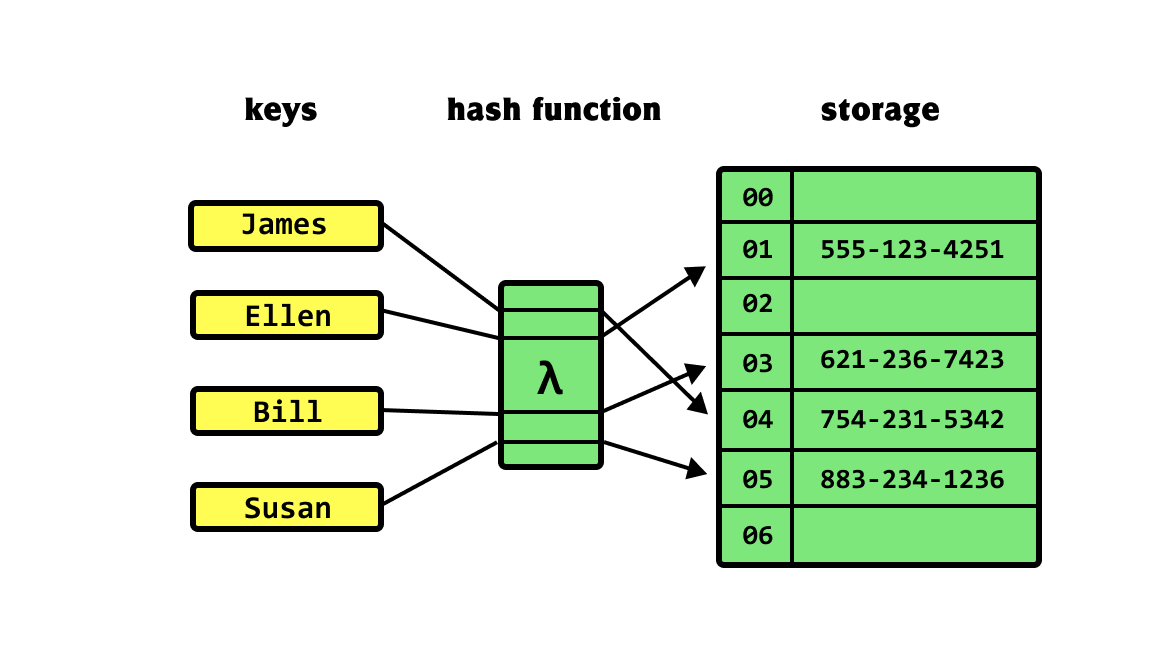
- If you want to add a key, say “Jane”, it undergoes a hashing algorithm. This is much simpler and less cryptographic than something like SHA-256 (Cryptographic Hash Functions).
- This can be as simple as as taking , where is the length of the (current) table and key is the (integer representation of the) key. The result would be the key.
- Accessing a value in the Hash Table is .
- If the table crosses a threshold of (typically ), then a new table is created and copied over. The expansion may seem inefficient, but the Amortised Cost is reasonable.
What if the Hash Function produces a key already in use?
This is known as a collision. It’s inevitable really. The key to making a Hash Function quick is dealing with these quickly. A simple way of solving this is just skip to the next empty slot and throw it in there. But there’s many algorithms for handling collisions.
Picture Painting 1000 Words: