In Machine Learning, What Are LLMs (I.E Transformer)?
Conceptually (Excruciatingly, Painfully Simplified): AI model that reads a lot of sentences, learns abstract representations of languages’ many concepts. It takes its learnings and generates text based on them.
- Can also be thought of as a lossy compression algorithm.
Practically: They’re a collection of matrices. That’s it. When you multiply a sentence (represented by vectors) by your LLM, you get another matrix. This represents the most likely next words in the sentence. You can then take one of those words, add it to the sentence and then take the whole sentence and feed it right back to the start (this is where “auto-regressive” comes from).
Transformer Architecture:
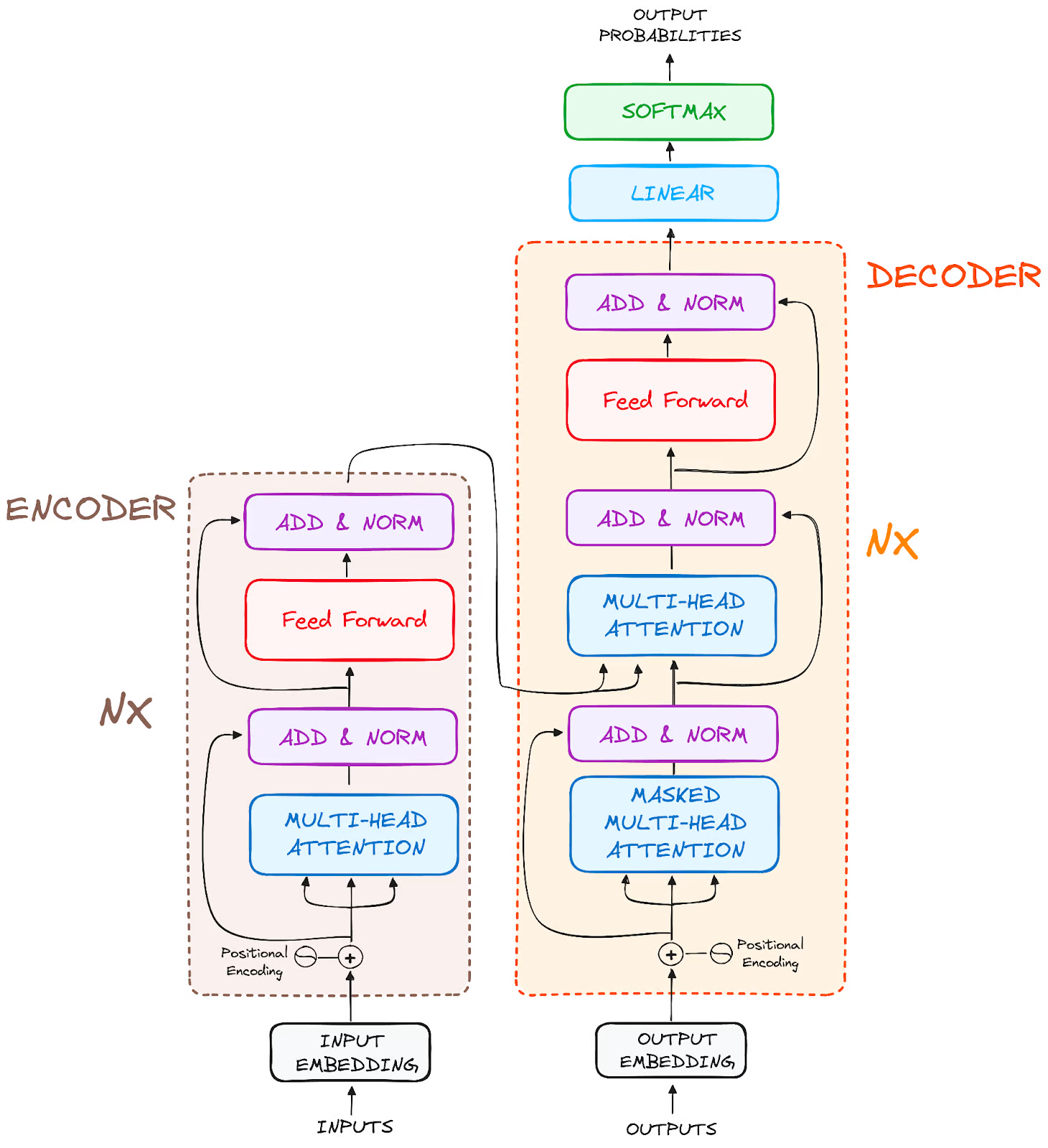
How Does It Work?
0. Components / Glossary:
-
Deep Learning Recap: In most of ML, we avoid hard If-This-Then-That rules. Instead, we create tuneable weights (like knobs and dials in an ML Model). By feeding in examples, the model adjusts these weights to fit the data. With a new input, it predicts a reasonable output. (Simple Linear Regression illustrates this: the knobs are the slope and -intercept.)
-
Encoder-Decoder Model: The (original) Transformer is an Encoder-Decoder Model. This means it takes the input text, converts it to embeddings and rewrites the entire text into a context-aware vector representation (encoder). Then, it iteratively reconstructs that back into an understandable form (decoder).
- This is good for Translation and Summarisation.
- The interim compressed vector is a bottleneck - can lose critical details, latent space might not have sufficient details, inefficient for long sequences etc.
-
Decoder: ChatGPT is a decoder-only model. It simply takes the text’s embeddings and predicts the probabilities of the next word.
- Decoder only is literally only good for next word prediction. But it’s really good at it.
-
(Un)Embeddings: We need a way of representing language mathematically. We use our good friend, Vector Embeddings. TL;DR:
- We represent words as vectors.
- Nearby vectors are words with similar semantic meaning.
- Direction in vector space has some (often unknown) meaning
- We can also turn Math back into language, by taking the a vector representing language, applying Softmax Function to it and taking (one of) the most probable words.
- Note 1: LLM’s don’t split up into words, instead they split into tokens (subsets of words). This makes life easier later on
- Note 2: It’s not exclusively language. Often images, sound bytes, etc.
-
Attention Mechanism: Words in language depends on the context surrounding it. We developed a mechanism for that. Read how it works here.
-
Multi-Layer Perceptrons (MLP): The most simple Neural Network there is.
1. Walking Through The Diagram; Encoder:
- We take each word and convert convert them to vector embeddings.
- We add a way to encode the position in the sentence in which the word came (Positional Encoding).
- We now want to change all of the words’ embeddings (i.e. representations in vector space) so that they (the embeddings) take into account the context.
- I.E. we want to turn the embedding for “tower” (which likely represents tall looming things) to French metal structures when we have “Eiffel” in front of it. We’d want to change it even more when we’ve got “Miniature Eiffel Tower”. Ideally the “Tower” embedding is now somewhere close to other small, touristic attractions (and maybe even close to keychains!).
- Read Attention (AI) for more details.
- We take take the output of our updated embeddings and normalise them.
- We then feed that into a Feed Forward MLP. It’s here where (scientists are pretty sure anyways) most of the memorisation of facts happen. (We suspect it’s stored in the weights).
- We then stack many encoders on top of each other. The hope is that the more layers they go through, the more nuanced their understanding of word embeddings are. So instead of Lear referring to a King, the embedding refers to a patriarchal self obsessed figure, emblematic of unchecked hedonism and vanity (but only after having read the entire play).
2. Decoder:
- It looks largely the same as the encoder.
- In the decoder’s 2nd attention layer, it actually takes Query and Keys from the encoder. The values, are from the decoder. This is known as Cross Attention. This allows every token in the output to attend to every token from the input.
- Again, this is useful for stuff like translation.
3. Finally:
- You take the final vector’s embedding.
- Pass that through an MLP.
- Apply a softmax through it.
- You have a probability for every single next possible word.
- We sample from the next most likely possible words.
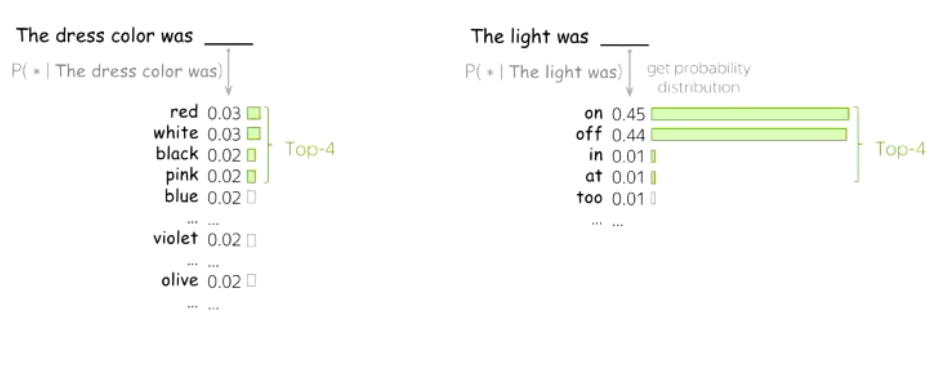
Wait! Why not just take the most likely word?
If we did, the text becomes incredibly robotic, predictable and uncreative (i.e. greedy decoding / deterministic - this would be good for translating for example!). Instead, if we randomly sample all of the top words whose probability sums to (e.g. 0.9), we get far more engaging language. This approach is called Nucleus Sampling (Top-P Sampling).
Note: We could also just take from the top-k most probable words, but what if there’s a word that’s so obviously the next word? Or what if there’s many equally likely words that could come next?
Learn More:
I gave a very high level view of the basics of it. This article and 3b1b were great in helping me learn this in the first place.
Cool Thing to Think About 🤔
It’s not immediately obvious, but LLMs are (the first?) Machine Learning models that you can improve the accuracy of without changing the weights… You just have to include few-shot examples in the context. This is known as In-Context Learning - it was quite the shock as everybody thought you needed fine-tuning. Also, we don’t fully understand why it works lol.
It’s helpful as:
- Labelling brand new data is expensive, this only requires a few examples.
- Finetuning is expensive
- Transfer skills exist.
ChatGPT:
There’s many different types of transformers, but the one that blew up the world was The Generative Pretrained Transformer, in a Chat format, by OpenAI.