What is it?
A form of model-based prediction. Used for continuous variables, as opposed to Classification which is for discrete categories.
How do you do Linear Regression (and Machine Learning in general):
- Specify the model
- Specify the loss function
- Minimise the loss
How does it work?
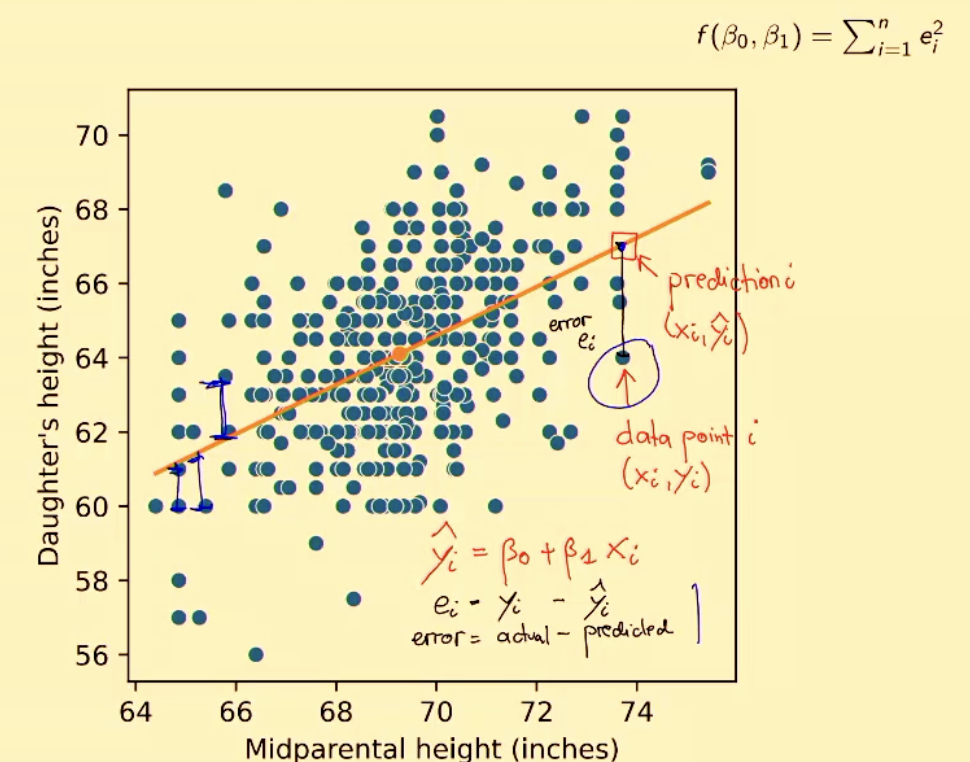
- We assume x and y are related by:
- Note: This is very similar to the equation of a line.
- We optimise the model to be the line with the smallest average distance to all of the lines ().
- In English: Square each prediction’s distance from the line and add them up.
- Mathematically, that looks like:
- The Loss is called Quadratic Loss or Sum of Square Errors.
- Note: Squaring the loss penalises overshooting and undershooting as equally bad.
- Minimise the loss.
Example of above:
Optimisation Techniques for Linear Regression
A common way to optimise for the correct ‘s is the following formulae, known as ‘Least Squares Estimate’.
Optimal Solutions:
Once you have an optimised line, there’s still points that don’t go through it (technically still errors). They’re known as Residuals.
Smallest Loss Achievable:
The optimisation here lies in minimising the residuals. Why? Well because if your line is as close to all points not on the line as possible, and no alterations could make them closer, then you’ve the best fitting model. The formula for that (I.E. The smallest possible loss)?:
Dissecting The Formula:
- : The number of data points
- : Variance of target
- Predicting something that’s more variable is much harder. Thus as the variability increases, smallest possible loss also increases.
- : Regression Co-efficient.
- If , is perfectly correlated with . If , is perfectly non-correlated with
- Loss decreases as