What:
It’s not immediately obvious, but LLMs are (the first) Machine Learning models that you can improve the accuracy of without changing the weights and biases. You just have to include a few-shot examples in the context.
This was discovered and claimed in an OpenAI paper. This was quite the shock to people, as most believed to improve on language tasks, you needed to fine-tune your models.
Why this mattered:
- Labelling new data is expensive. If we could add examples, and the model would use it’s internal intelligence to connect the dots, then boom.
- Fine-tuning is expensive.
- Transfer skills exist.
The Catch:
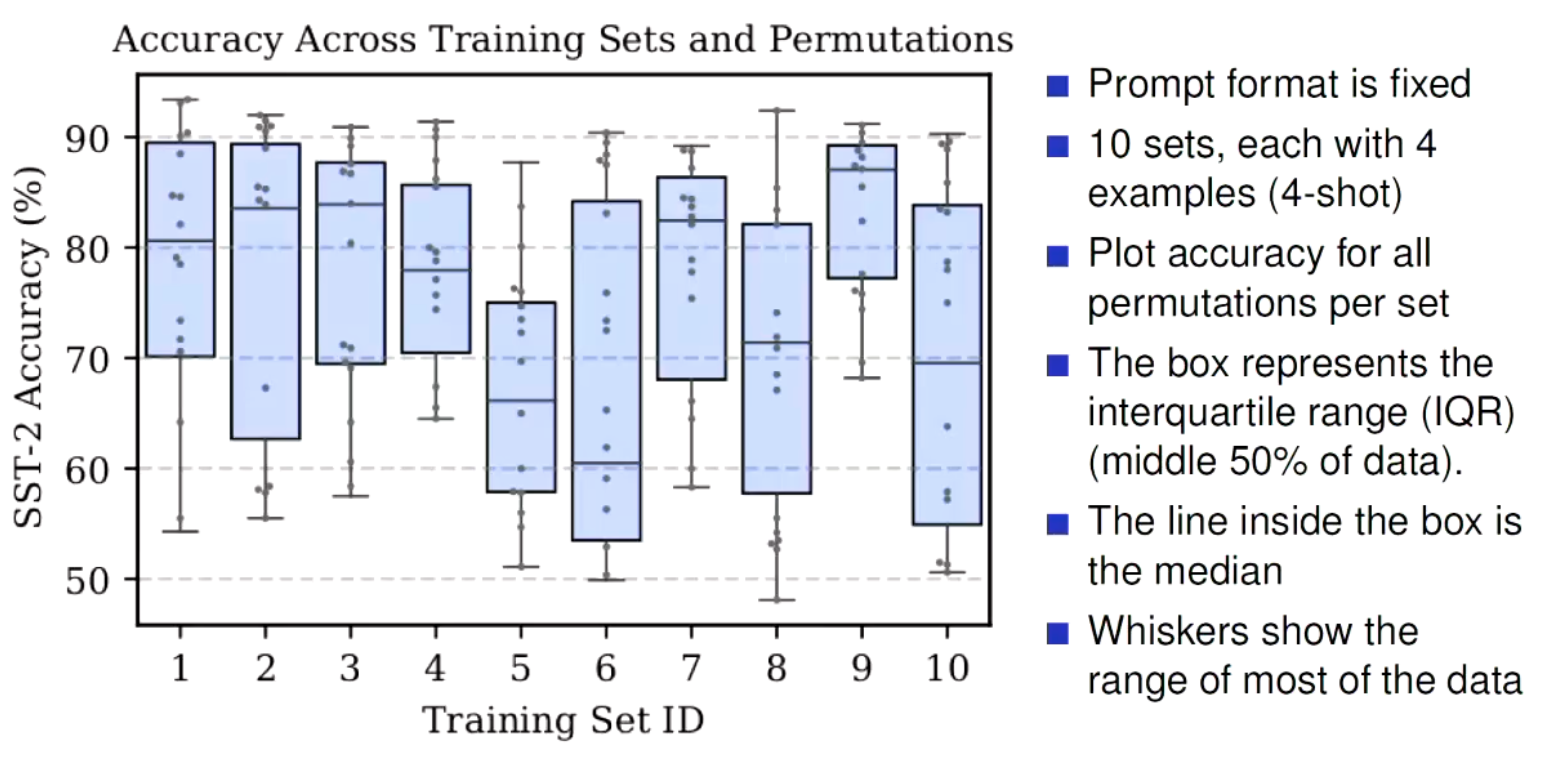
There’s a infinite ways to prompt engineer your way to success. For example, what’s the difference between the 2 following examples of few shot learning your way to success.

Also, how do you select the best examples to pick? Or how do you select the order at which the examples appear?
That’s really well represented here. For example take the 6th training set. Depending on how you changed the order of the examples, the accuracy varied by ~40%!!