What?
It’s a a part of the Gradient Descent algorithm. It’s the part in charge of actually changing the weights and biases in your neural network.
Key Idea:
Sure. As we learned in the Derivative note, you can think of the gradient of a function as the direction of the steepest slope in your high-dimensional space. But if it’s more than 3, we measly humans just can’t conceptualise that slope.
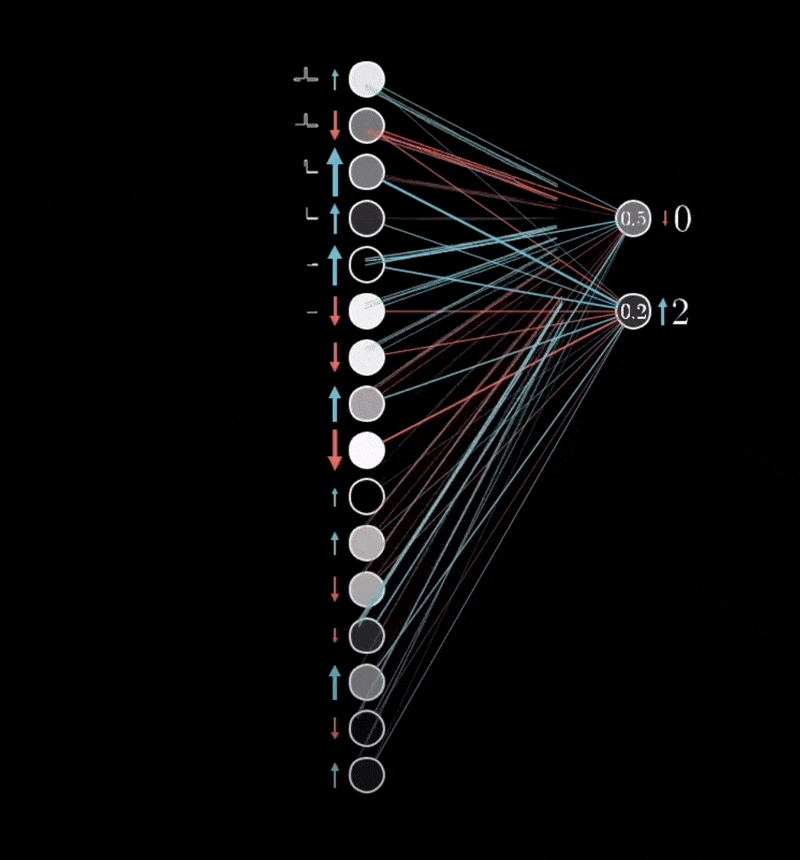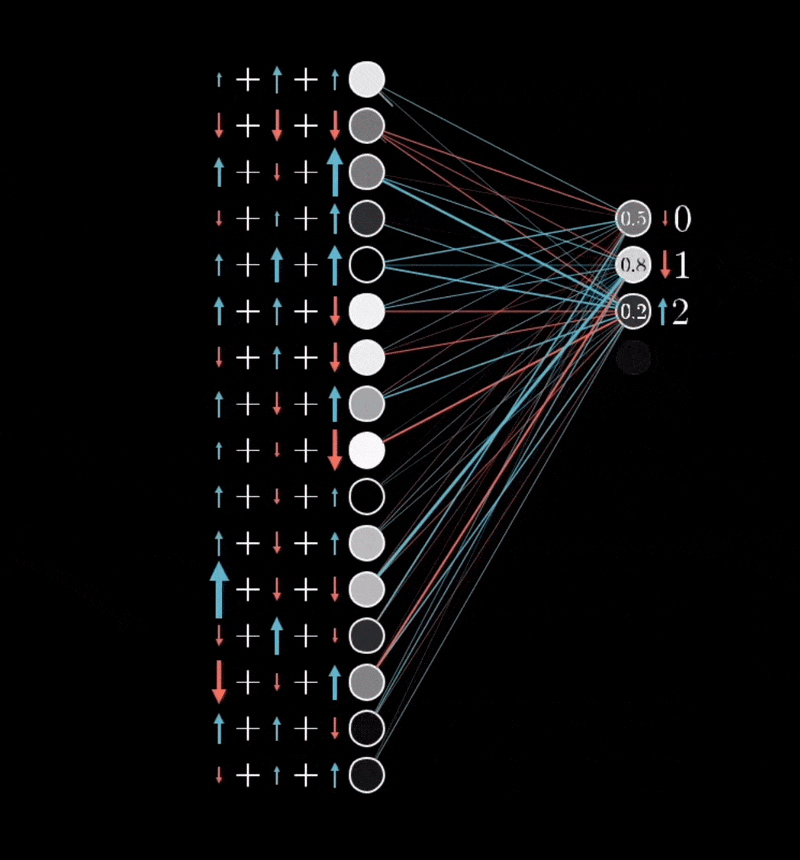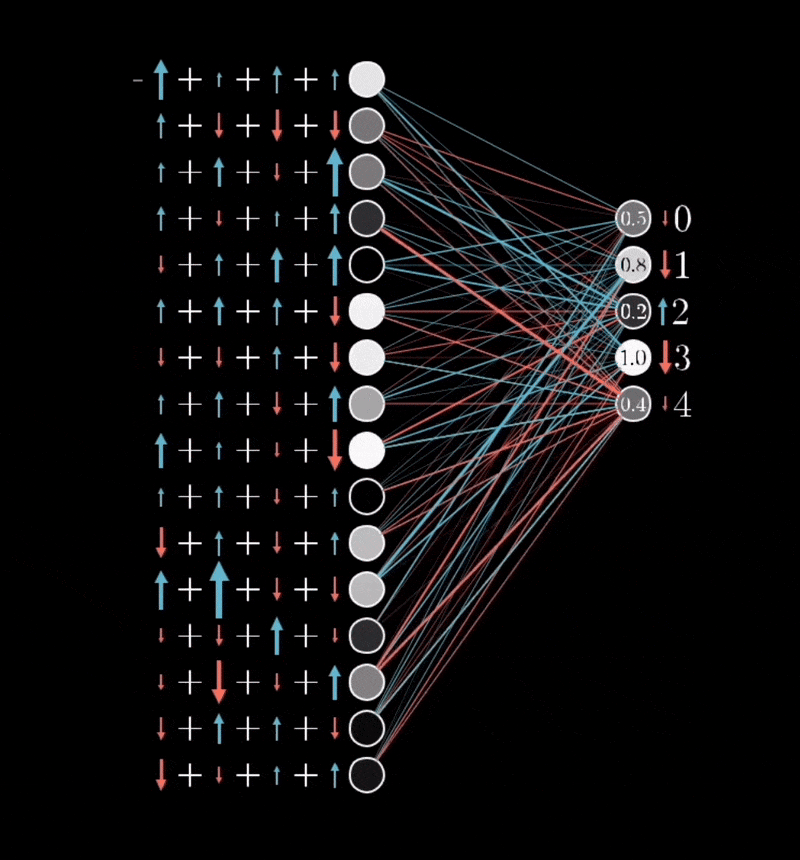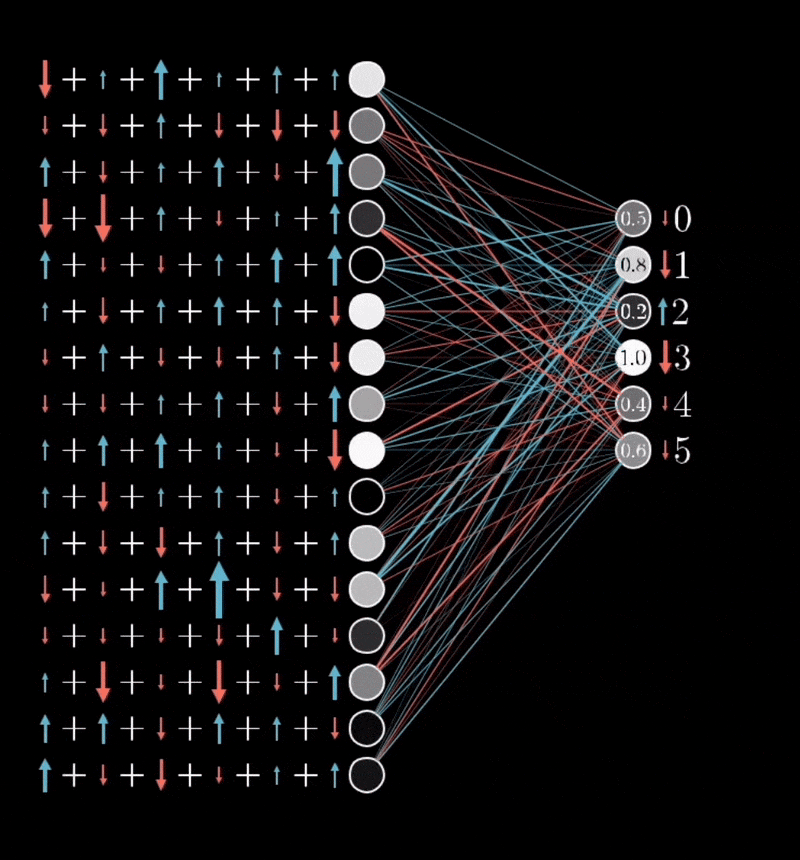
So what’s a better way of conceptualising it? Take the gradient vector, . Remember, each row corresponds to a weight in that layer:
- The sign of the row corresponds to whether it should increase or decrease.
- The magnitude of each corresponds to how much it should change by.

The Process, Conceptually:
- Remember, this is just a subroutine of the larger Gradient Descent process.
- Once we calculate the gradient of the loss function , we effectively have:
- A vector () whose components tell us how much each weight should change.
- We then update each weight:
- Multiply each weight’s gradient by the learning rate , which is an arbitrary constant in Neural Networks.
- Subtract this value from the weight. (This ensures we step in the direction that reduces loss.)
- Remember, the gradient is naturally larger if the loss is larger. So when multiplying the it by the amount to step, we make it proportional to the slope. Thus, we take big steps when far away from the minimum, but small steps when close. (This is good!)
- Now, we move backwards through the network.
- We know that each neuron in the output layer contributed to the error.
- We adjust the weights leading into the output layer based on how much each neuron’s activation influenced that error.
- Once we have these weight updates for the hidden layer → output layer, we propagate the error backward into the hidden layers.
- If a neuron in a hidden layer needs to be less active, we modify the weights leading into it accordingly.
- This “backward propagation of errors” is why it’s called Backpropagation.
- Repeat this process for every training example in your dataset.
- Important: In practice, you don’t update weights after every single example.
- Instead, you batch your data, calculate the loss for that batch, compute the gradient for that batch, and then update the weights.
- (This is the difference between Stochastic Gradient Descent and Mini-Batch Gradient Descent.)
Actually Doing That, Mathematically:
The weight update follows the same rule as in Gradient Descent:
Where:
- represents the model parameters (weights).
- is the learning rate, which controls the step size in weight updates. (i.e. an arbitrary constant)
- is the gradient of the loss function with respect to .
More specifically:
- Gradient of the loss function with respect to weights:
Where is the actual feature. - Gradient of the loss function with respect to bias:
This means:
- If the predicted output is too high, we reduce the corresponding weight.
- If is too low, we increase the corresponding weight.
- This ensures the network slowly learns to make better predictions over time.
Batched Backprop:
Alternatively, if you’re doing batched backprop (almost always), you’d use:
Where:
- represents a specific weight
- is the learning rate, which controls the step size in weight updates. (i.e. an arbitrary constant)
- is the batch size
- is the formula for the weight ‘s gradient.
The Main Difference: With batched, you sum up every gradient in the batch and then divide by the batch count. This ends up looking a lot more “stumble-y”, but trains WAY faster.
P.S: You could also keep track of your momentum, and add another constant. That way, if you’ve been progressing quickly down the hill, your change in weight will reflect that.