What
We can calculate our Cross-Entropy Loss in our Neural Networks. Now, how do we actually reduce that loss?
Conceptually:
Take the following Neural Network, it’s got 784 inputs, 2 hidden layers, and 10 outputs.:
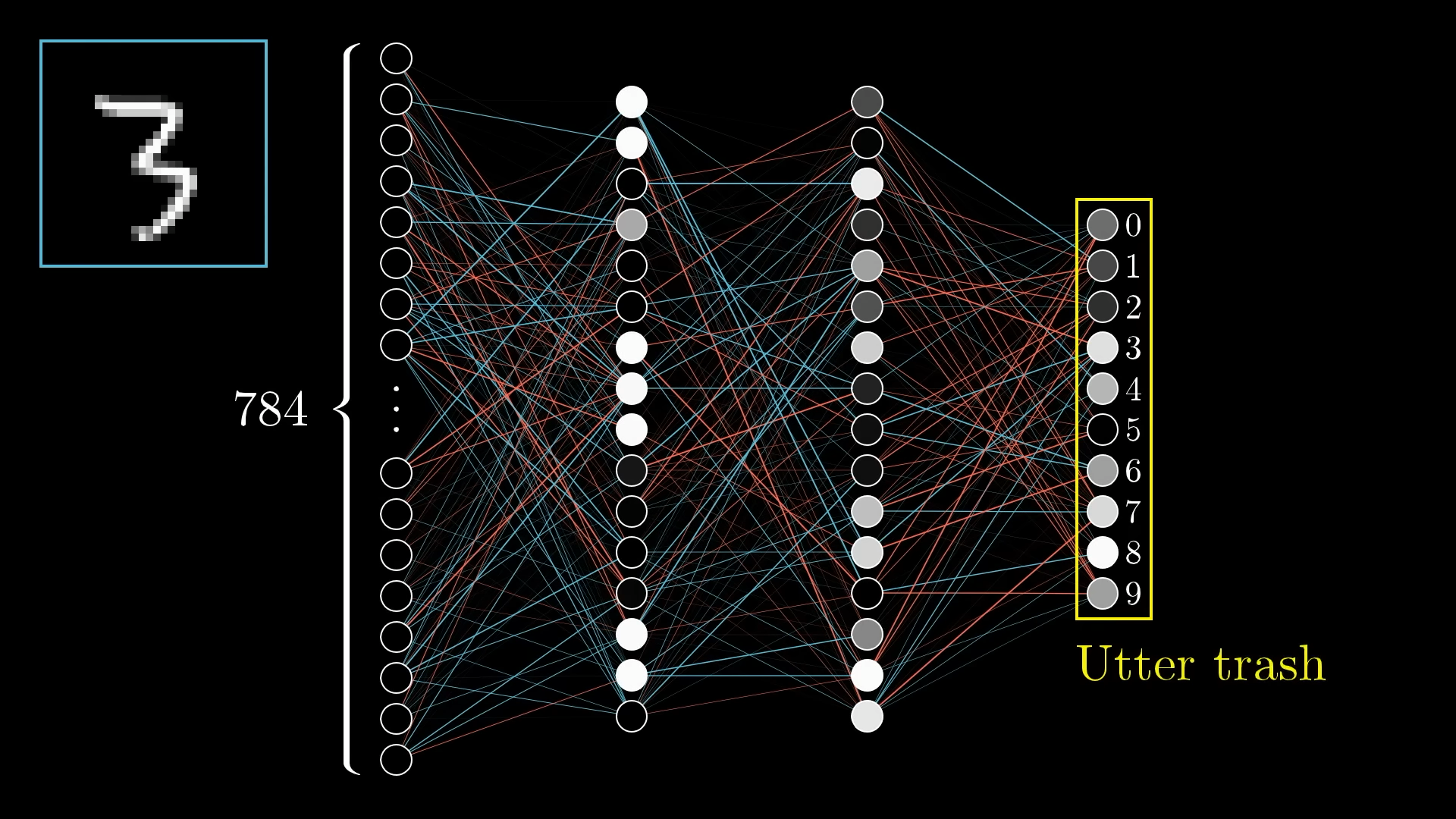
- You randomise everything; the weights and biases. The output is thus, to any given input, random.
- You calculate a cost of your output. How far was your output from the ideal one? (In reality, you do this across every class and sum up all of your losses.). In our example, it should be . Our error will be calculated using Cross-Entropy Loss.
- Since loss is essentially a function, where , we can plot that as some high-dimensional graph.
- From there, we find the direction in this high-dimensional space that coincides with the steepest decrease in the loss (i.e. the steepest downwards gradient). We use partial derivatives for that.
- From there, we want to try and take a tiny step down the hill in that direction. This means we need to change the weights and biases in some way to decrease the loss. We use Backpropagation for that.
- We repeat this process until: $$
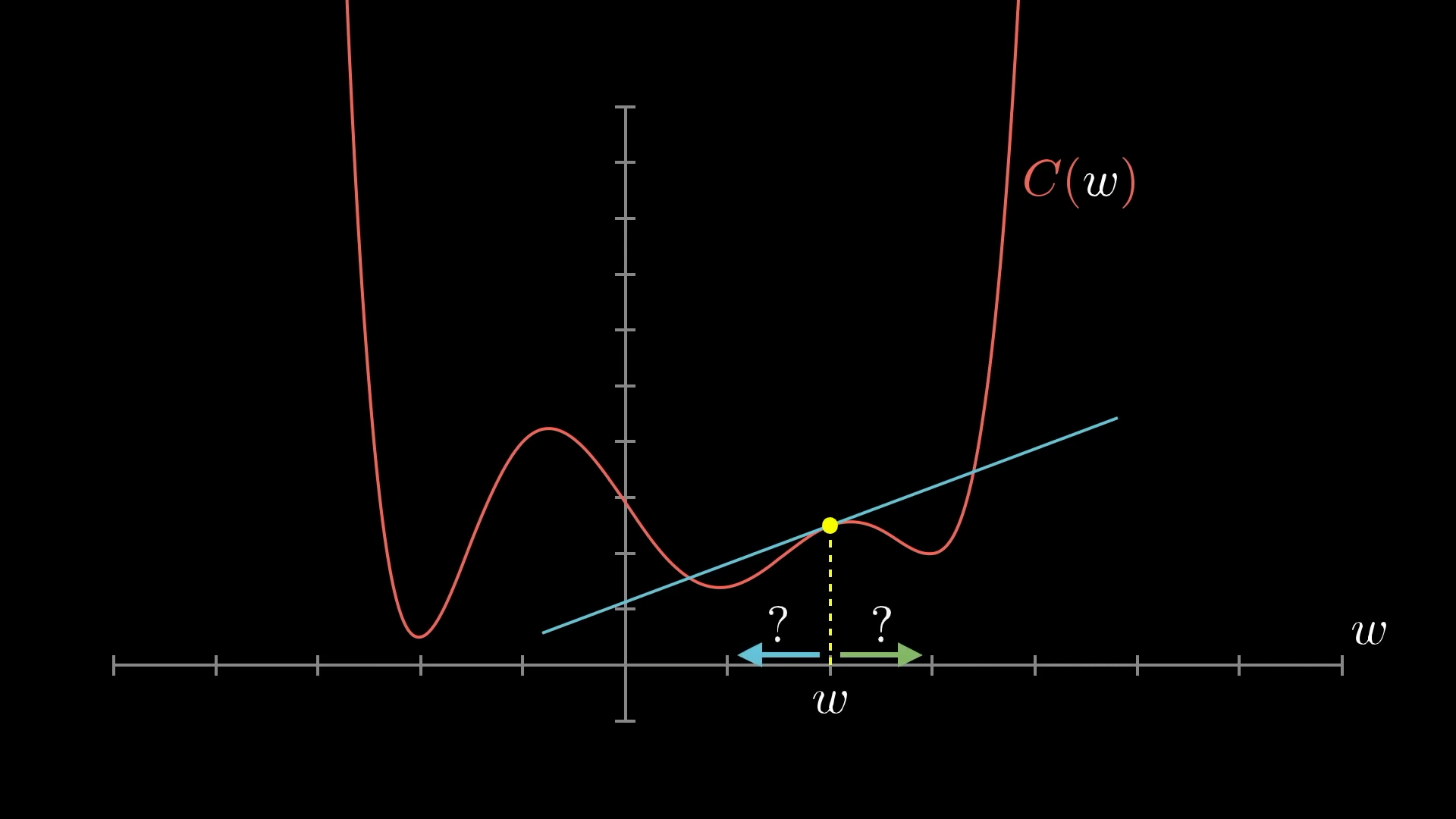
||\nabla_w L|| < \epsilon - Note: There’s no guarantee that the minimum we land at is the global minimum. We try and combat this by adding some “momentum” to our stepping.
Vanilla Vs. Stochastic 😈:
The only difference between what I just described and Stochastic Gradient Descent is that with stochastic, you batch your data, calculate the loss on each batch, calculate gradient descent (of that batch in total) (and then you do Backpropagation). This is much faster, but it’s a lot more “stumble-y” down the gradient as opposed to carefully and calculated vanilla (Gaussian Gradient Descent!).
Mathematically:
Where:
- represents the model parameters (weights).
- is the learning rate, which controls the step size in weight updates.
- is the gradient of the loss function with respect to .
Key Idea / Takeaway:
Sure. You can think of the gradient in GD as the direction of the steepest slope in your many dimensional space (as is mathematically defined). But if it’s more than 3, we measly humans just can’t conceptualise that. (The concept is derived in here)
So what’s a better way of conceptualising it? Take the gradient vector (). Remember, each row corresponds to a weight in that layer:
- The sign of the row corresponds to whether it should increase or decrease.
- The magnitude of each corresponds to how much it should change by.

Actually Doing That, Mathematically:
The gradient of the loss function with respect to weights is:
The gradient of the bias:
Adam Optimiser:
- Give parameters that receive infrequent updates a larger learning rate, and those that receive frequent updates a smaller learning rate.
- We estimates to adapt the learning rate for each paramter
- (missing details deffo)