What:
We designed this system of RL (albeit very weak form of RL) to keep AI models aligned to human values. Great conceptual explainer video is here.
Overview, Oversimplified:
(More details here)
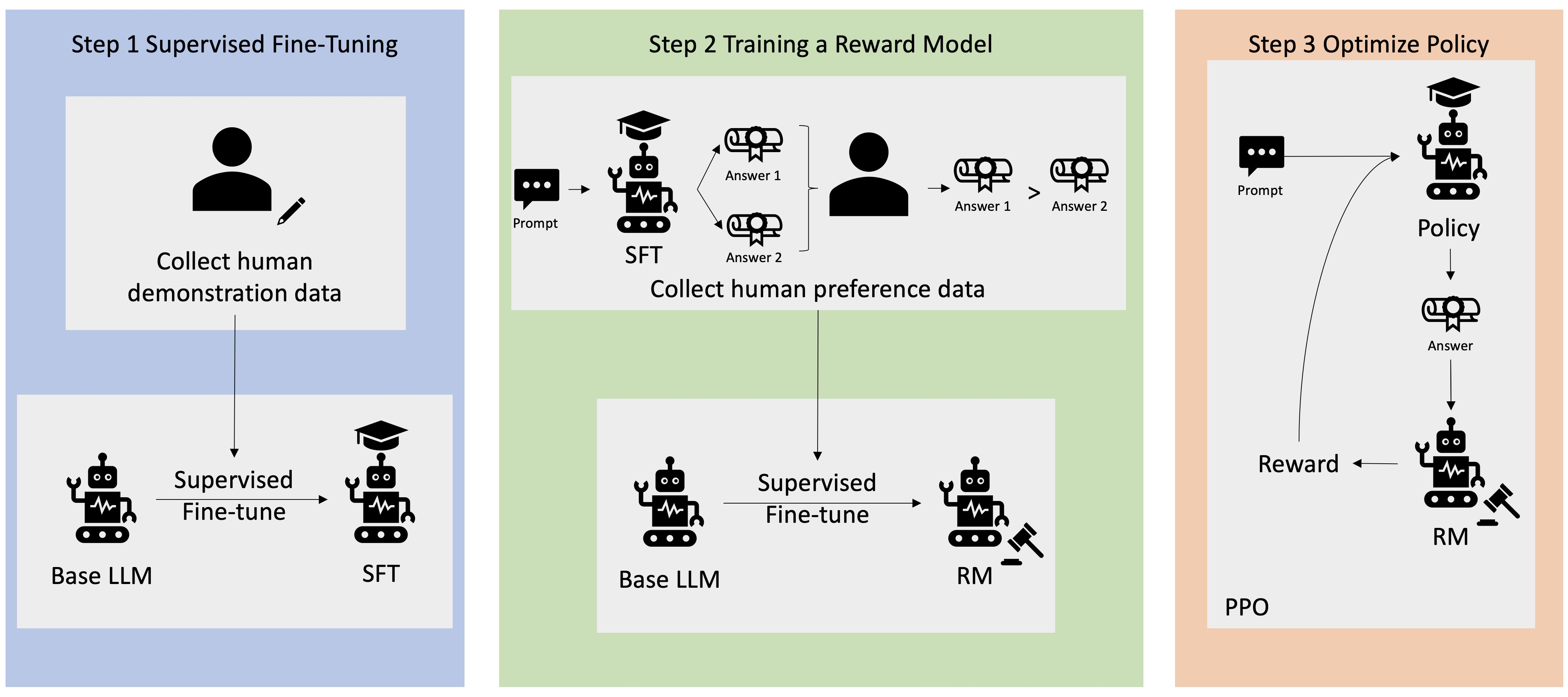
0. Models go through their normal pretraining. Now models are able to come up with coherent text. But this is imperfect - it outputs stuff against our values. The solution? Fine-tune it! Ok… But how?
- Using human annotators, create examples of good answer-response pairs. Fine-tune your LLM to produce answers like them. Now, get it to produce 2 answers to a prompt, and get a human to rank them against each-other.
- Take these rankings, and train another model to be a human annotator/ranker… We’ll call this the reward model.
- The reward model can now judge the base model based on human preferences. We’ll use that fact to do RL:
- We give our model a prompt, ask our RM to rate the answer, prize it using Proximal Policy Optimisation (PPO) and then feed that back into the policy.
The RL, a bit more in-depth:
- Setup, you have:
- A frozen, initial language model (base LM)
- A Tuned Language Model (being updated with PPO), aka a policy.
- A model trained to act like a human annotator (a reward model)
- You take a prompt. “A dog is…”
- You get both models to generate outputs
- You compute how much they differ / diverge by, using KL Divergence.
- You also, simultaneously, feed your policy’s output into the Reward Model.
- You combine the KL divergence with the reward model.
- It’s literally a sum: . You reward it for it for being aligned with human preferences, and punish it for a higher divergence from the Base LM.
- You take the total reward signal , and pass that into the PPO algorithm to see by how much the model has to update. Since we’re trying to maximise, not minimise, it’s actually gradient ascent.
- Repeat. Repeat it a lot.
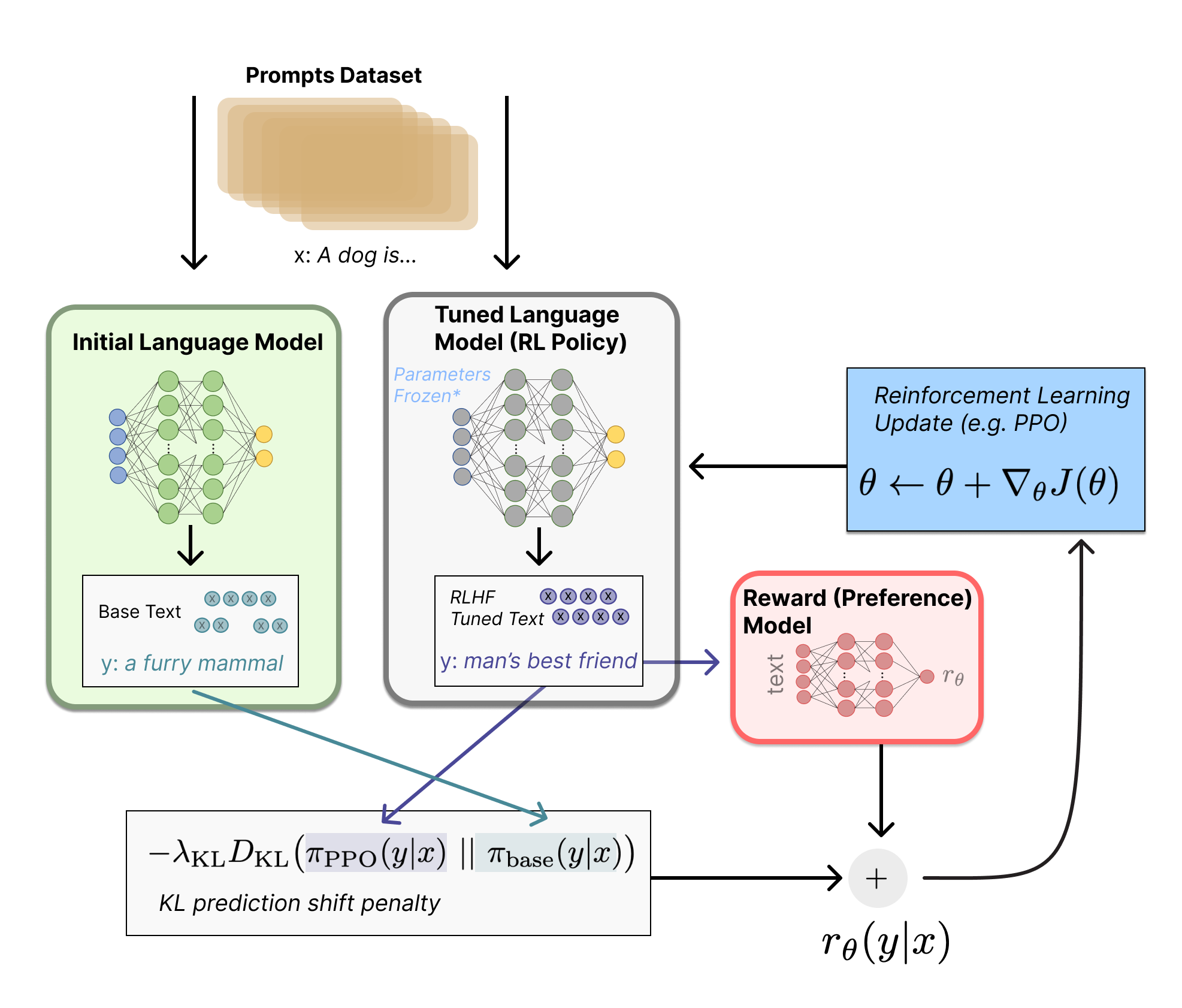
Why Include The Base LLM?
Imagine we didn’t include the base LLM, and so had no KL divergence. Well then the policy would learn to just output incoherent (but safe!) text. E.g. “puppies love happy playgrounds” etc.
Note on RM:
There’s a formula that you can use that takes a preference from A→B and returns a scalar.
Why Bother with Reinforcement Learning?
Have you ever thought about it? Why not just fine-tune your model to the user’s preferences? It would be a lot simpler no?
- Fine-tuning: is akin to telling the model “here’s the correct answer, memorise it”. This is an essential part of the process. Learn more about it here.
- RLHF: is akin to telling the model “here are two options, humans like this one more. Learn from that”.
With fine-tuning, you may have to give multiple examples of every possible behaviour we don’t want. RLHF learns the pattern of what not to respond to. Also, it implies that the human annotated response is the best possible response. RLHF leaves flexibility to learn something that humans prefer more.
Controversy 👀:
Andrej Karpathy has shat on RLHF, saying it’s basically not RL. Honestly, I’m inclined to agree. Basically:
- The Reward Model looks at the LLM’s output. Based on it’s general vibe (as decreed by humans), it encourages / discourages it. It’s a crappy proxy (as opposed to the better but abstract goal of “Reward it based on how ‘correct’ it was” - what does it mean to be correct?).
- You also don’t get the creativity of RL. It’s the traditional AlphaGo vs AlphaZero.
AKA Instruction Tuning
Models that have been instruction tuned perform better to unseen tasks. Interesting innit.