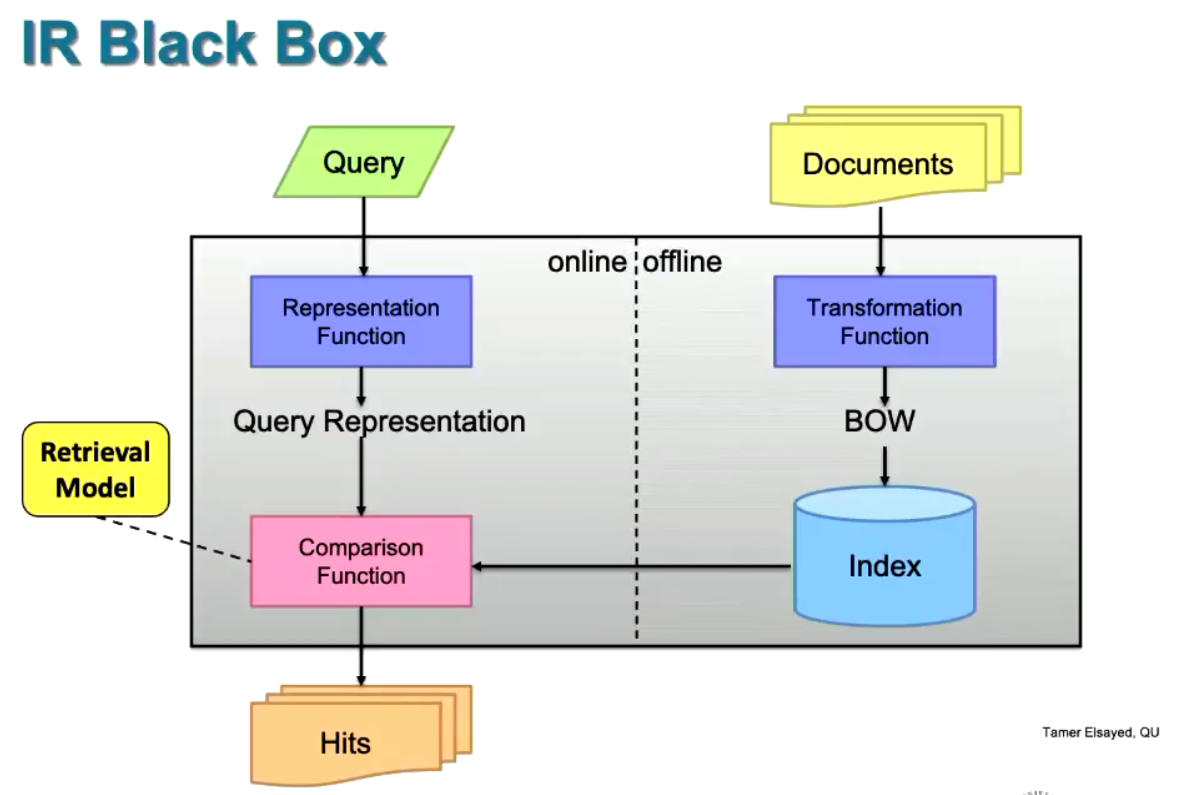
What:
- Finding specific, unstructured material that satisfies an information need from within large collections.
Pipeline:
When preparing to do large scale Information Retrieval (IR), you need to first index all of the data. Here’s the pipeline:
- Decide the data you’re looking for
- Aquire those documents
- Crawlers, RSS feeds, emails etc.
- Store all of those documents in a document store
- Transform all of the text (Pre-Processing in IR)
- Stemming (or lemmatising)
- Stopping
- Create an index (index) of all of that data
- You’ve now got a lookup table for quickly finding all docs containing a word.
- You’ve got multiple kinds:
- Collection Index
- Positional Index
- Proximity Index
- Extent Index
- Permuterm Indexes
- Then do the searching. Again, you’ve got multiple kinds:
Problems Presented:
IR needs to be:
- Effective
- Find relevant things
- Efficient
- Needs to find them quickly
Components:
- Documents:
- The unstructured element you’re retrieving (has a UUID)
- May not even be words at all (e.g. DNA)
- Queries:
- Free text that represents user’s information need.
- Multiple queries can describe the one information need (e.g. “Current POTUS” and “Donald Trump”)
- Can also be one query represents many different things (e.g. “Apple”)
- Free text that represents user’s information need.
Relevance:
- How do we decide what to show? Based on if the user will click it? If it satisfies the user’s info need? Novel?
- Relevance: Relevant items will be similar